Java原理探索:AQS的技术体系之CLH、MCS锁的原理及实现
背景
SMP(Symmetric Multi-Processor)
对称多处理器结构,它是相对非对称多处理技术而言的、应用十分广泛的并行技术。
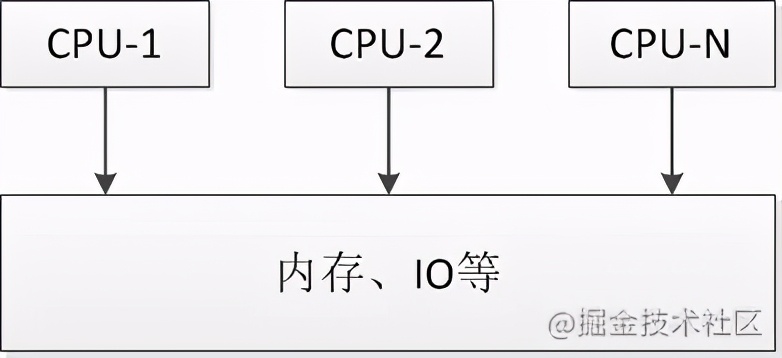
- 在这种架构中,一台计算机由多个CPU组成,并共享内存和其他资源,所有的CPU都可以平等地访问内存、I/O和外部中断。
- 虽然同时使用多个CPU,但是从管理的角度来看,它们的表现就像一台单机一样。
- 操作系统将任务队列对称地分布于多个CPU之上,从而极大地提高了整个系统的数据处理能力。
- 但是随着CPU数量的增加,每个CPU都要访问相同的内存资源,共享资源可能会成为系统瓶颈,导致CPU资源浪费。
NUMA(Non-Uniform Memory Access)
非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问。
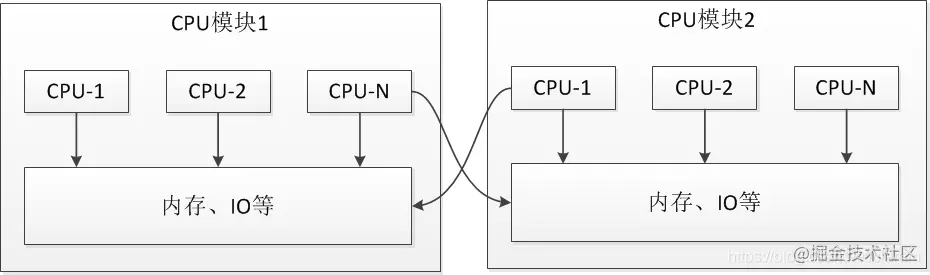
- 访问本地内存(本CPU模块的内存)的速度将远远高于访问远程内存(其他CPU模块的内存)的速度,这也是非一致存储访问的由来。
- NUMA较好地解决SMP的扩展问题,当CPU数量增加时,因为访问远地内存的延时远远超过本地内存,系统性能无法线性增加。
CLH锁
CLH是一种基于单向链表的高性能、公平的自旋锁。申请加锁的线程通过前驱节点的变量进行自旋。在前置节点解锁后,当前节点会结束自旋,并进行加锁。
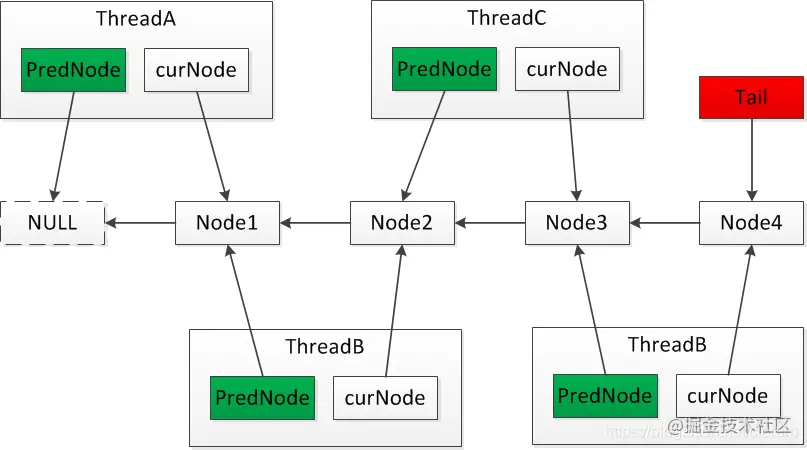
- 在SMP架构下,CLH更具有优势。
- 在NUMA架构下,如果当前节点与前驱节点不在同一CPU模块下,跨CPU模块会带来额外的系统开销,而MCS锁更适用于NUMA架构。
加锁逻辑
- 获取当前线程的锁节点,如果为空,则进行初始化;
- 同步方法获取链表的尾节点,并将当前节点置为尾节点,此时原来的尾节点为当前节点的前置节点。
- 如果尾节点为空,表示当前节点是第一个节点,直接加锁成功。
- 如果尾节点不为空,则基于前置节点的锁值(locked==true)进行自旋,直到前置节点的锁值变为false。
解锁逻辑
- 获取当前线程对应的锁节点,如果节点为空或者锁值为false,则无需解锁,直接返回;
- 同步方法为尾节点赋空值,赋值不成功表示当前节点不是尾节点,则需要将当前节点的locked=false解锁节点。如果当前节点是尾节点,则无需为该节点设置。
public class CLHLock { private final AtomicReference tail; private final ThreadLocal myNode; private final ThreadLocal myPred; public CLHLock() { tail = new AtomicReference(new Node()); myNode = ThreadLocal.withInitial(() -> new Node()); myPred = ThreadLocal.withInitial(() -> null); } public void lock(){ Node node = myNode.get(); node.locked = true; Node pred = tail.getAndSet(node); myPred.set(pred); while (pred.locked){} } public void unLock(){ Node node = myNode.get(); node.locked=false; myNode.set(myPred.get()); } static class Node { volatile boolean locked = false; } }复制代码MCS锁
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同:CLH是在前 趋结点的locked域上自旋等待,而MCS是在自己的结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。
MCS锁具体实现规则:
- a. 队列初始化时没有结点,tail=null
- b. 线程A想要获取锁,将自己置于队尾,由于它是第一个结点,它的locked域为false
- c. 线程B和C相继加入队列,a->next=b,b->next=c,B和C没有获取锁,处于等待状态,所以locked域为true,尾指针指向线程C对应的结点
- d. 线程A释放锁后,顺着它的next指针找到了线程B,并把B的locked域设置为false,这一动作会触发线程B获取锁。
public class MCSLock { private final AtomicReference tail; private final ThreadLocal myNode; public MCSLock() { tail = new AtomicReference(); myNode = ThreadLocal.withInitial(() -> new Node()); } public void lock() { Node node = myNode.get(); Node pred = tail.getAndSet(node); if (pred != null) { node.locked = true; pred.next = node; while (node.locked) { } } } public void unLock() { Node node = myNode.get(); if (node.next == null) { if (tail.compareAndSet(node, null)) { return; } while (node.next == null) { } } node.next.locked = false; node.next = null; } class Node { volatile boolean locked = false; Node next = null; } public static void main(String[] args) { MCSLock lock = new MCSLock(); Runnable task = new Runnable() { private int a; @Override public void run() { lock.lock(); for (int i = 0; i < 10; i++) { a++; try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(a); lock.unLock(); } }; new Thread(task).start(); new Thread(task).start(); new Thread(task).start(); new Thread(task).start(); }}
