C++入门(六)之String
目录
一、为什么学习string类?
C语言中的字符串
算法题使用
二、标准库中的string类
string类
string文档介绍
string的底层简介
中文的编码表
string的头文件
三、string类的常用接口说明
构造函数
string类对象的容量操作
(1) 计算对象的长度 size与lengh
(2) max_size
(3)capacity
(4)clear
(5)string的增容reserve与resize
(7) empty
string类对象的访问及遍历操作
(1)operator [ ] 对字符串进行遍历
(2)迭代器进行遍历
(3) 范围for 自动往后迭代,自动判断结束(C++11才支持)
(4) 反向迭代器 倒着遍历
(5)const 迭代器
(6) at
string类对象的修改操作
(1)插入字符
(2) c_str
(3) find与rfind及substr
(4)insert
(5)erase
string类非成员函数
(1)operator +
(2) 流提取和流插入
(3)比较大小
(4)stoi(string to int)
(5)to_string
(6)getline
一、为什么学习string类?
C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
算法题使用
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数
二、标准库中的string类
string类
我们可以通过这个网址string - C++ Reference 去了解彼岸准库中的string是怎样去定义。
string文档介绍
- 1. 字符串是表示字符序列的类
- 2. 标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
- 3. string类是使用char(即作为它的字符类型,使用它的默认char_traits和分配器类型(关于模板的更多信息,请参阅basic_string)。
- 4. string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用char_traits 和allocator作为basic_string的默认参数(根于更多的模板信息请参考basic_string)。
- 5. 注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作。
总结:
- 1. string是表示字符串的字符串类
- 2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- 3. string在底层实际是:basic_string模板类的别名,typedef basic_string string;
- 4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include以及using namespace std;
string的底层简介
通过文档简介我们知道string的原生类是一个类模板,大致如下:
typedef basic_string string;templateclass basic_string{private:T* str; //...};我们不经想到,为什么字符串类型会是T,字符串类型不就是char类型吗,难道还有别的类型?
这个地方就与编码有关,计算机是由美国人发明的,早起计算机只是显示英文的。显示英文就比较的简单,单纯的需要26个英文字母进行组合就可以,算上大小写,及标点符号一共也就128个,去表示常见的英文绰绰有余。计算机存储英文(只有二进制)编码就是一个值与对应的符号建立映射关系,这个映射关系就叫做编码表。英文的编码表就是ASCII表,用来表示英文。
ASCII码值的意思就是指:你表示的一个字符在内存当中存储的时候对应的那个整形值(用二进制存储的)
eg1:大写字母A的ASCII码意思是在机器内存中是以数字65的2进制形式存放的。
eg2:对这个字符串数组而言,实际上存的这些字符对应的值(语言规定字符串以\0 结束)
int main(){char str[] = "hello";return 0;}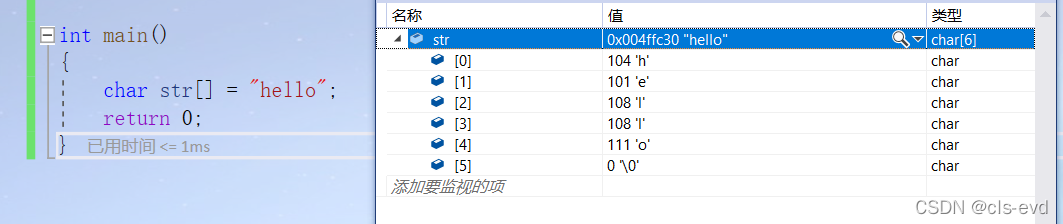
后来为了计算机在全世界普及,不能仅仅只适用英语,由此出现了Unicode表示全世界文字编码表,同时Unicode又包含ASCII,utf-8,utf-16,utf-32等等。
中文的编码表
英文,每个字母对应一个值就可,而一个字节8个比特位,就有2^8个(256)状态,所以对于英文很容易就表示完了。如果用一个字符去表示一个中文,最多就只能表示256个汉字,这是远远不够的。一个字节不够,两个字节来凑,两个字节就有2^16种状态,就能表示65000多个汉字,但是如果表示一个汉字的比特位越多,就代表着汉字占的空间就越大,这是非常不好的,utf-8,就是将一些常见的汉字用2个字节去编写,生僻的字用3个或4个去编写,并且指定一系列的规则。不同值对应不同汉字...,Linux下默认的就是utf-8。
eg:存的是对应的值,要显示的话用这些值去对应的表里去查
int main(){char str[] = "喝水";return 0;}
还有一个有意思的事情就是,我们对字符串++,文字的内容是会改变的

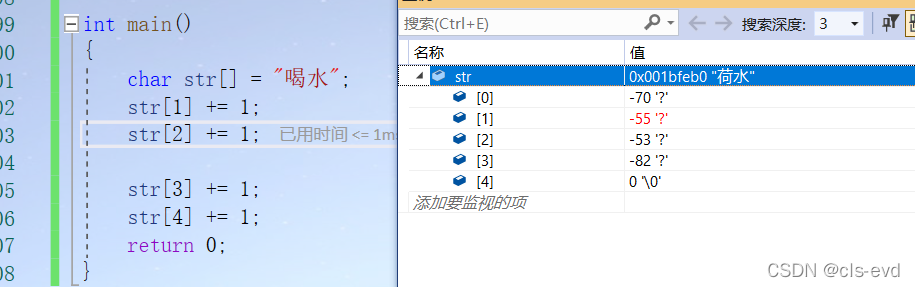
所有的编译器都允许选编码,如果编译器的编码和你所写的对应不上就会出现乱码 windows在中国受众者多,所以给中文自己量身定做了编码表--gdk,windows下默认编码的就是gdk,
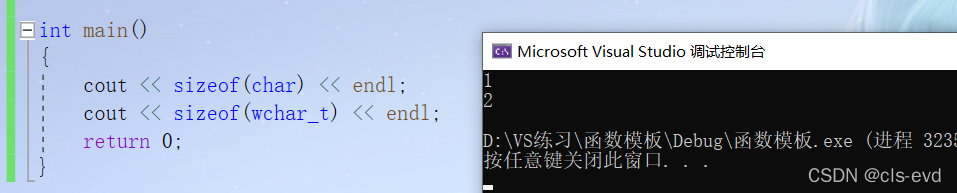
基于一些编码的原因,有些字符串就会用两个字符去表示,所以就有了wchar_t;如果是有wchar_t,就建议使用wstring(匹配wchar_t)
string的头文件
string的头文件是#include用的时候切记加上
如果不包头文件,这样写是可以编译通过的
但是使用流插入和流提取就会报错(VS2013)
可vs2019就不会
博主还是建议包上这个头文件,有总比没有强。
三、string类的常用接口说明
构造函数
打星的非常重要,其余可以了解
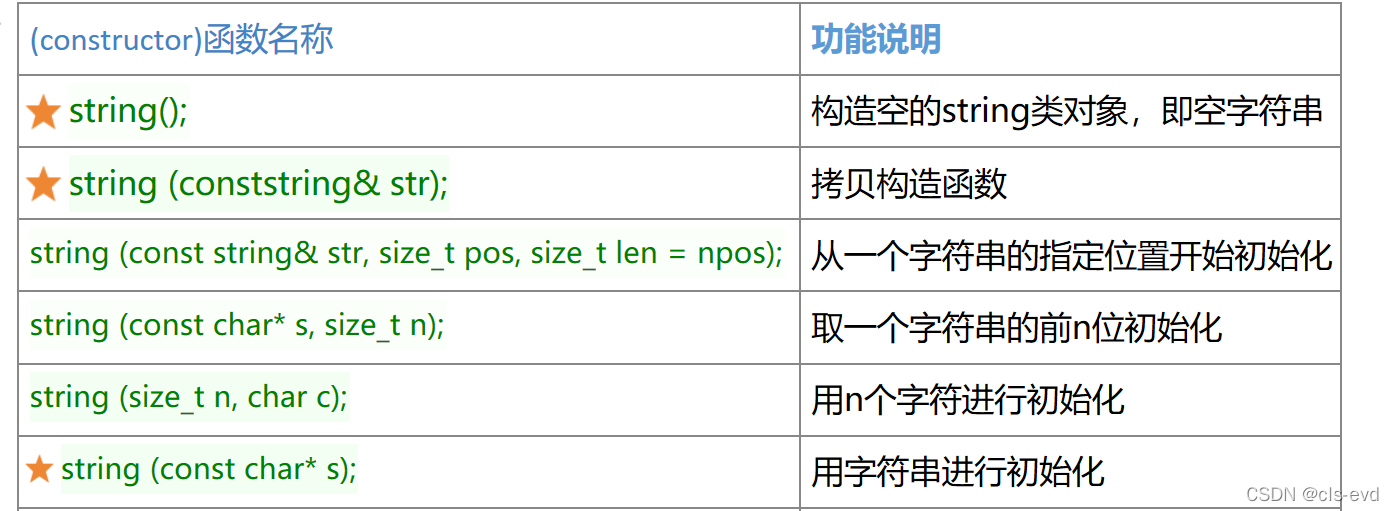
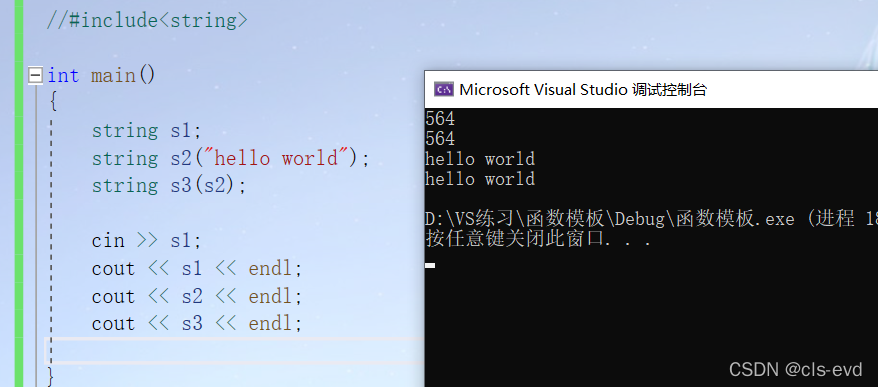
(1)无参构造,带参构造,拷贝构造
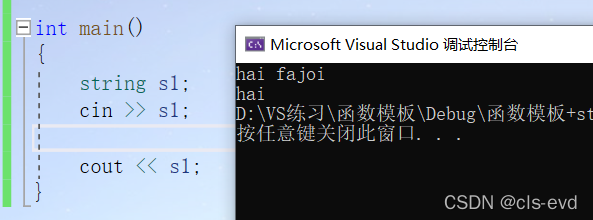
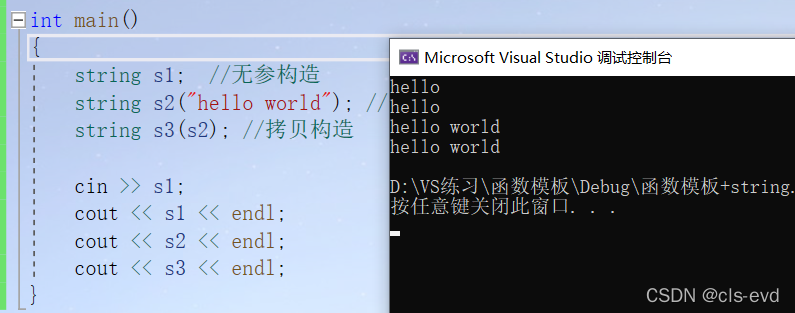
int main(){string s1; //无参构造string s2("hello world"); //带参的string s3(s2); //拷贝构造cin >> s1;cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;}
(2)
string (const string& str, size_t pos, size_t len = npos);pos代表从那个位置开始 。len代表拷贝的长度,这个len给了一个缺省值npos,代表的就是从该位置取以后所有的字符直到结尾。ps:npos的值就是-1,-1给给无符号的就是整形的最大值(-1的补码是全1,给给无符号的就是整形的最大值)
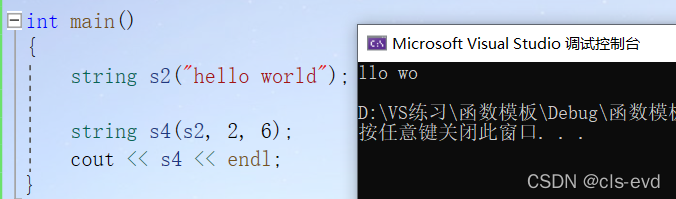
int main(){string s2("hello world"); //带参的string s4(s2, 2, 6);cout << s4 << endl;}
s4:从s2第二个位置开始,拷贝后面的6个字符。
eg2:
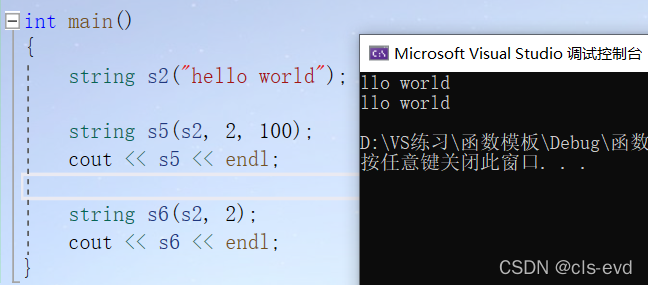
int main(){string s2("hello world"); //带参的string s5(s2, 2, 100);cout << s5 << endl;string s6(s2, 2);cout << s6 << endl;}
↑s5:从s2第二个位置开始,拷贝后面的100个字符。
s6:从s2第二个位置开始,拷贝后面的所有个字符(证明缺省值npos)。
(3)
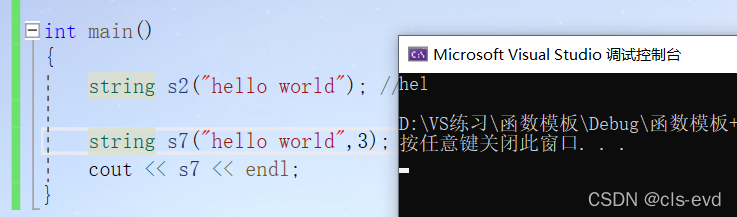
string (const char* s, size_t n);int main(){string s2("hello world"); //带参的string s7("hello world",3);cout << s7 << endl;}
s7:去hello world 的前三个字母初始化
(4)
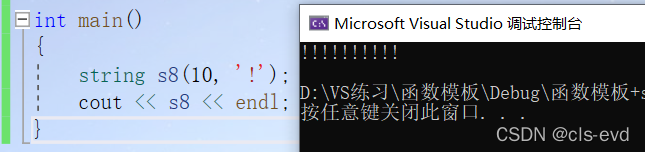
string (size_t n, char c);int main(){string s8(10, '!'); //看起来有用实际没用cout << s8 << endl;}
s8:用10个!初始化
string类对象的容量操作

(1) 计算对象的长度 size与lengh
int main(){string s1;cin >> s1;//不包含最后作为标识符的\0,算的是有效字符的长度cout << s1.size() << endl; //重要cout << s1.length() << endl; //了解}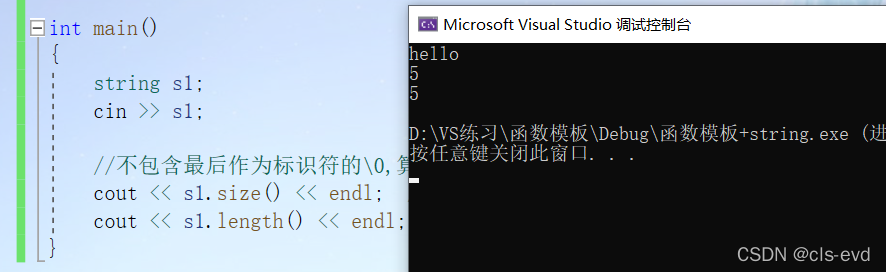
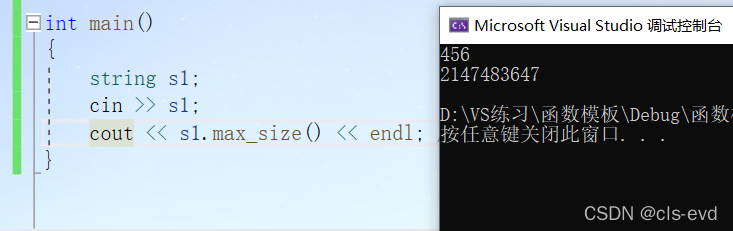
(2) max_size
功能:告诉我们这个字符串最长能有多长(与内存有关)
(3)capacity
功能:告诉我们这个字符串的容量有多大(就是最多能存多少个字符)
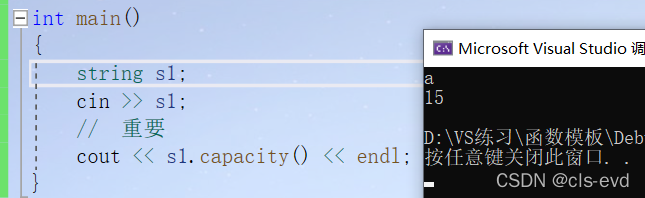
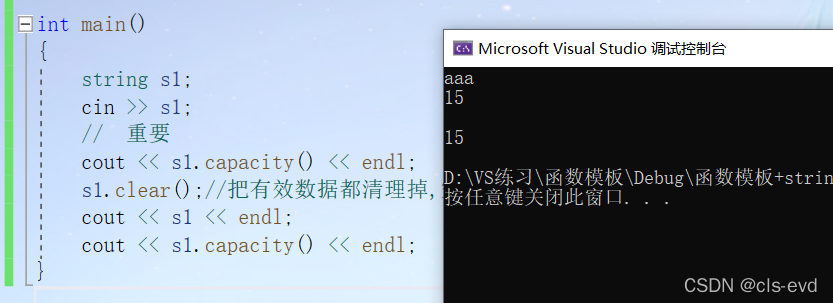
虽然显示的是15,但实际的空间是16,因为有个\0, 但是容量指的是能存多少个有效字符。
(4)clear
功能:把有效数据都清理掉,空间保留
(5)string的增容reserve与resize
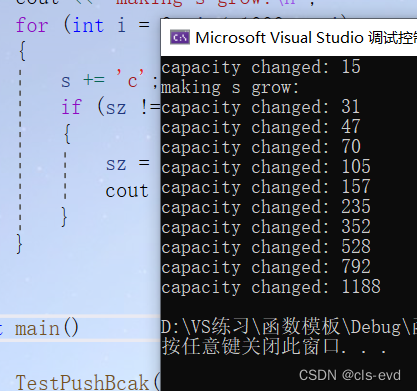
以下是自动string自动扩容的一段程序,通过结果得出增容一般情况下会1.5倍的进行增容
void TestPushBcak(){string s;size_t sz = s.capacity();cout << "capacity changed: " << sz << endl;cout << "making s grow:\n";for (int i = 0; i < 1000; ++i){s += 'c';if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << endl;}}}int main(){TestPushBcak();}
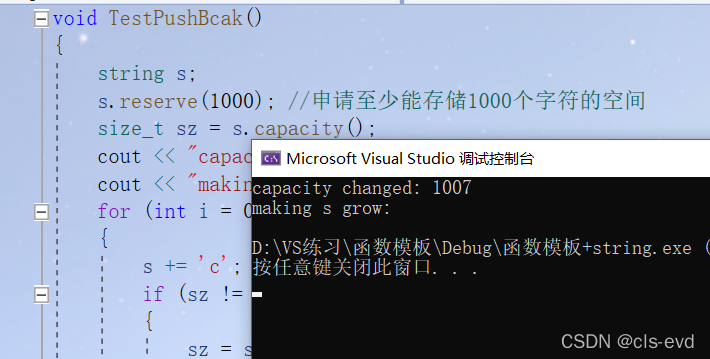
但是每次增容都是有代价的,而且这个代价是不小的,如果你已经知道你需要多少空间,你是可以利用reserve减少增容的代价。
reserve 只开空间,影响容量,可以改变string的容量。
void TestPushBcak(){string s;s.reserve(1000); //申请至少能存储1000个字符的空间size_t sz = s.capacity();cout << "capacity changed: " << sz << endl;cout << "making s grow:\n";for (int i = 0; i < 1000; ++i){s += 'c';if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << endl;}}}int main(){TestPushBcak();}
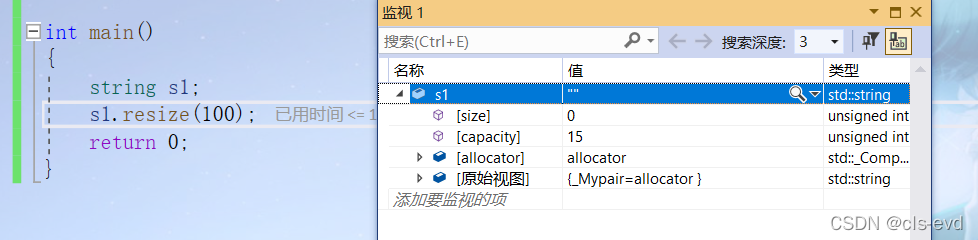
resize 是将字符串中的有效字符个数改为n个,当字符个数增多时,会对多出来的空间给一个初始值,进行初始化,默认初始值是 /0 ;
开始s1 里面的size是0,capacity是15
使用resize后,size被扩成了100,capacity因为size的改变而改变,且这100个size都填充成立 /0 .
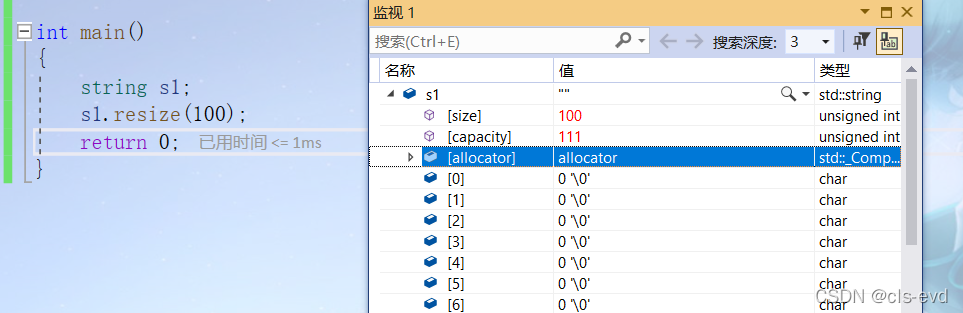
resize也可以自定义初始值
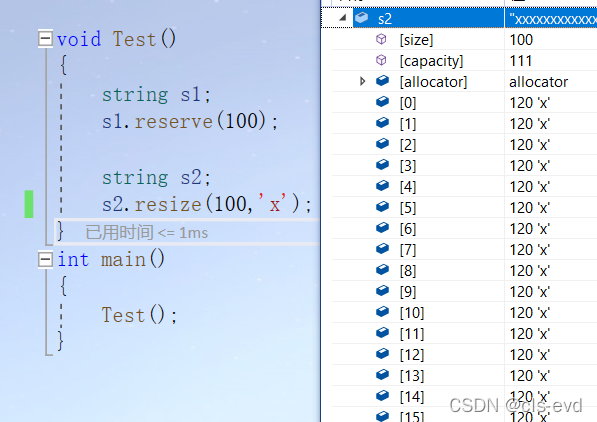
reserve与rsize的异同
reserve只是单纯的改变容量,rsize是改变有效字符个数,进而改变容量,并且会对改变的有效字符个数进行初始化
void Test(){string s1;s1.reserve(100);string s2;s2.resize(100);}int main(){Test();}
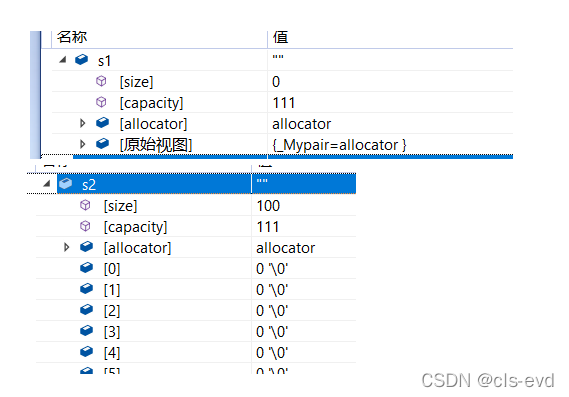
用reserve和resize进行扩容并不会影响之前的数据
但是如果用resize缩小size就会删除数据
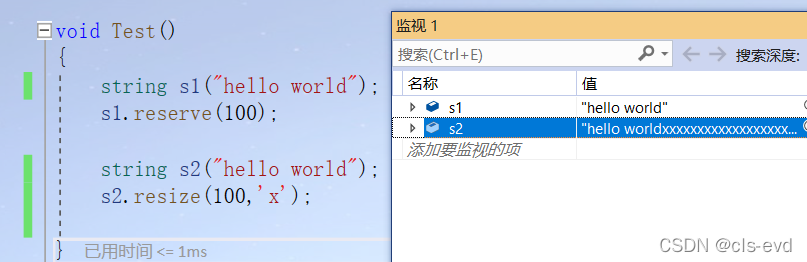
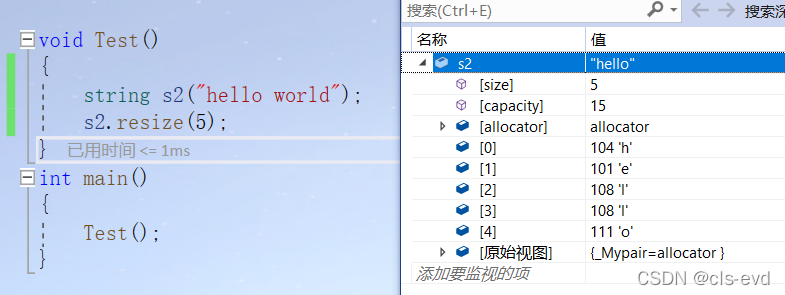
对于string而言reserve更有用。
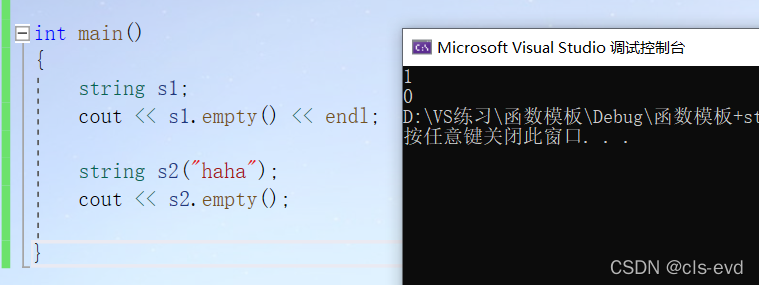
(7) empty
功能:判断字符串是否为空
string类对象的访问及遍历操作
 (1)operator [ ] 对字符串进行遍历
(1)operator [ ] 对字符串进行遍历
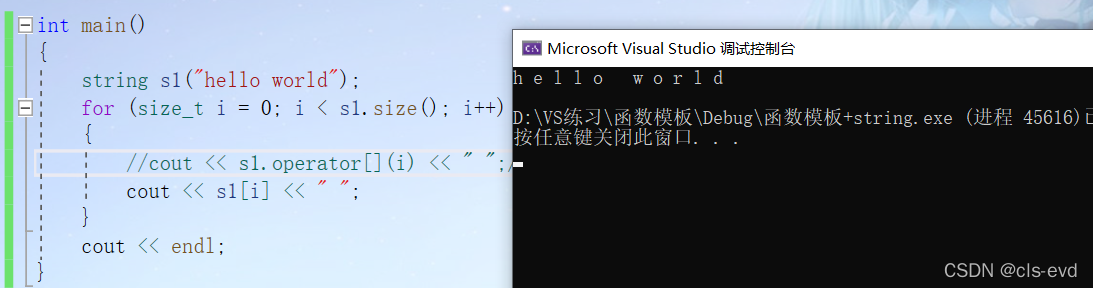
char& operator[] (size_t pos);const char& operator[] (size_t pos) const;eg1:遍历字符
int main(){string s1("hello world");for (size_t i = 0; i < s1.size(); i++) //读每个位置的字符{//cout << s1.operator[](i) << " ";//本质调用cout << s1[i] << " ";}cout << endl;}
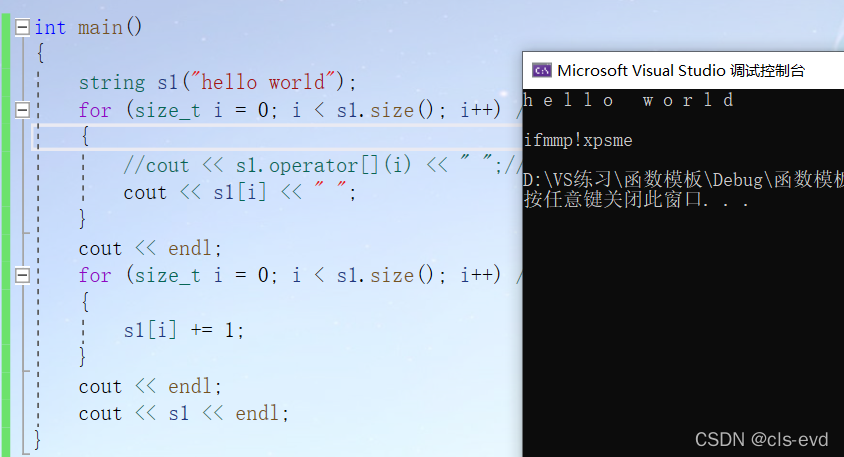
eg2: 修改字符,每个字符+1后都改变了
int main(){string s1("hello world");for (size_t i = 0; i < s1.size(); i++) //读每个位置的字符{//cout << s1.operator[](i) << " ";//本质调用cout << s1[i] << " ";}cout << endl;for (size_t i = 0; i < s1.size(); i++) //写每个位置的字符,operator[]的返回值是这个地方的引用{s1[i] += 1;}cout << endl;cout << s1 << endl;}
为什呢能进行修改呢?
因为[ ] 的返回值是char 类型的引用。
//实际底层实现char& operator[](size_t pos){ //... return _str[pos];}//底层是一个字符串数组,如果想修改第i个位置的字符,就返回这第[i]个位置的引用编译器编译会转换成是 s1.operator[](i),然后这个函数调用会有一个返回值,这个返回值是第i个位置那个字符的引用,对他加等,赋值就可以修改第i的值,所以这里的引用是为了修改这个地方的值,出了作用域这个对象还在,因为这个数组是开在堆上的,堆上出了作用域不受影响
这里的引用返回不是为了减少拷贝,而是为了支持修改对象
(2)迭代器进行遍历
用法及说明:
eg:修改及遍历字符
int main(){string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;it = s1.begin();while (it != s1.end()){*it += 1;++it;}cout << endl;it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}}
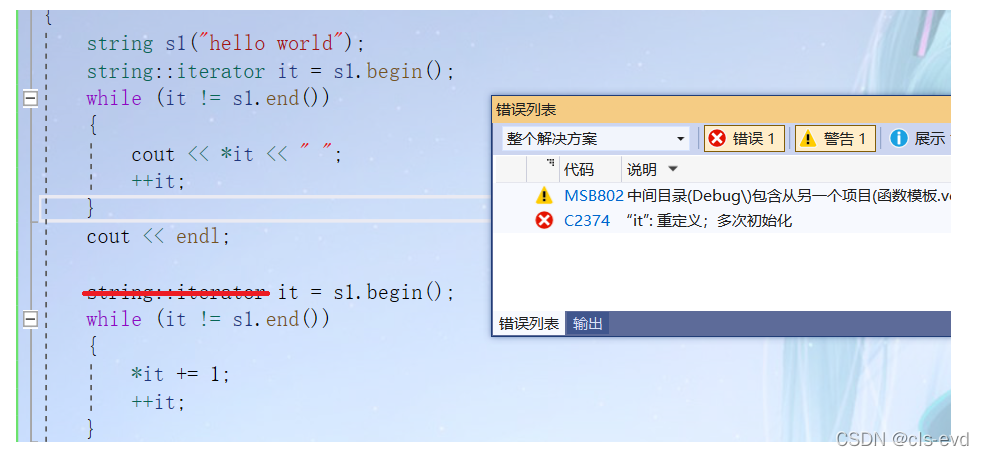
it是一个像指针一样的东西,但是它又不一定是个指针,在这可以认为是个指针。这个迭代器是内嵌类型是在string类里面定义的,所以要指定类域。
把迭代器想象成像指针一样的类型
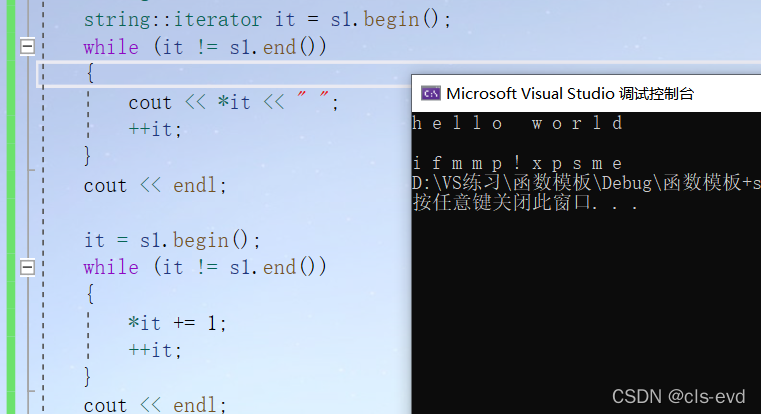

PS:第二次调用it的时候,就不用在写string::iterator了,不用定义it了,但还是得重给他初始化。
(3) 范围for 自动往后迭代,自动判断结束(C++11才支持)
eg1:遍历字符
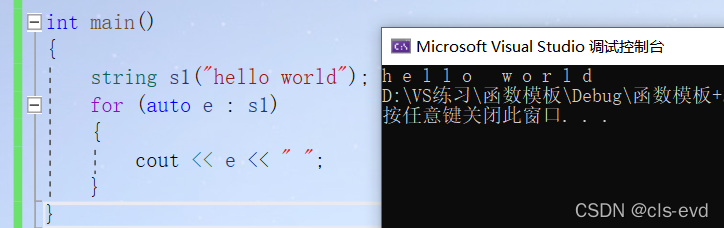
int main(){string s1("hello world");for (auto e : s1){cout << e << " ";}}
eg2:修改字符
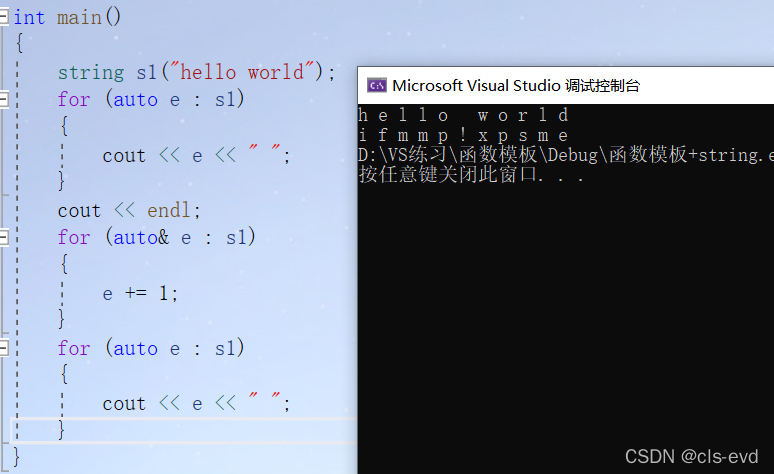
int main(){string s1("hello world");for (auto e : s1){cout << e << " ";}cout << endl;for (auto& e : s1){e += 1;}for (auto e : s1){cout << e << " ";}}
(4) 反向迭代器 倒着遍历
int main(){string s1("hello world");string::reverse_iterator rit = s1.rbegin();while (rit != s1.rend()){cout << *rit << " ";++rit;}}

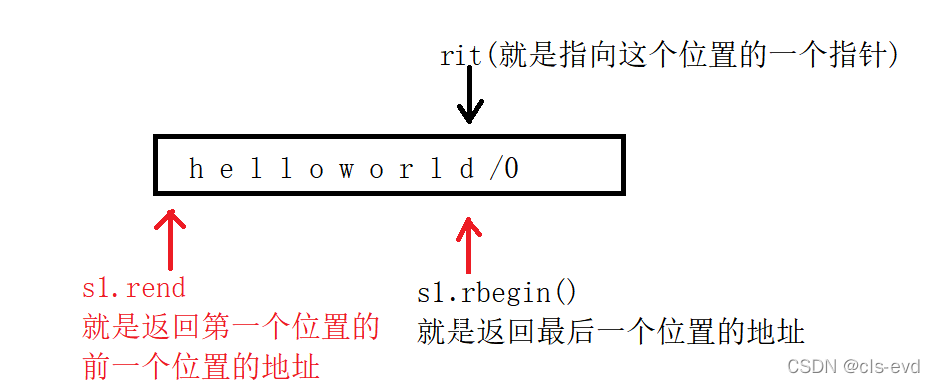
ps:用auto自动推到出它是迭代器也是可以的
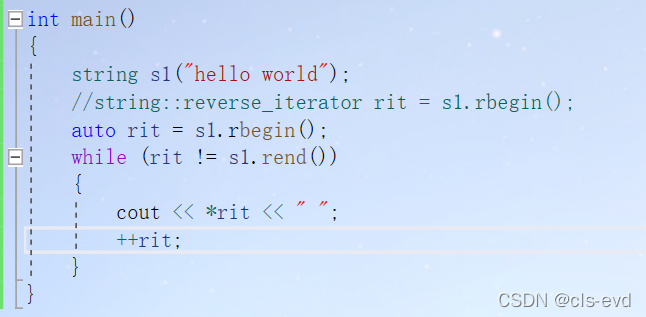
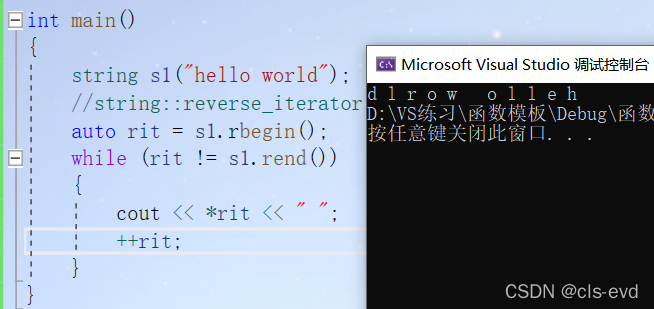
问题1:迭代器遍历的意义是什么呢?
对于string,无论正着遍历还是倒着遍历,下标+[ ]都足够好用,为什么还需要迭代器呢?对于string来说下标和 [ ] 就足够好用,确实可以不用迭代器。但是对于其他容器(数据结构)呢?
迭代器的意义就在于所有的容器都可以使用迭代器这种方法去修改访问。而且你会了一种容器的迭代器,其他容器的迭代器就差不多都会了。所以对于string,你得会用迭代器,但是对于string来说,一般我们还是喜欢下标+[ ]。
eg:list,map/set,不支持下标+ [ ] 遍历
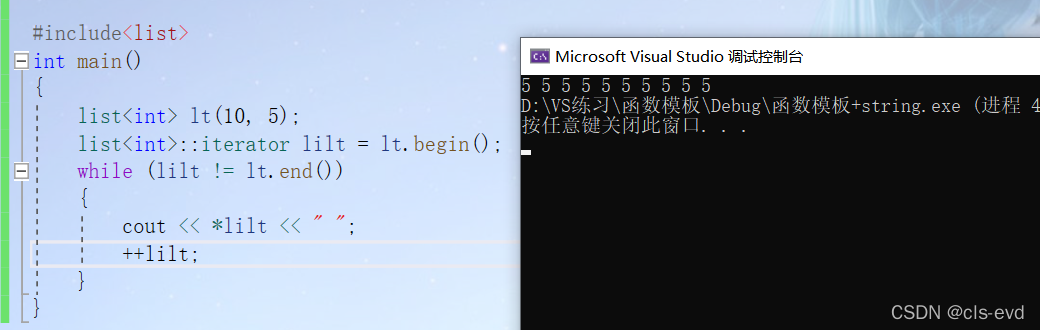
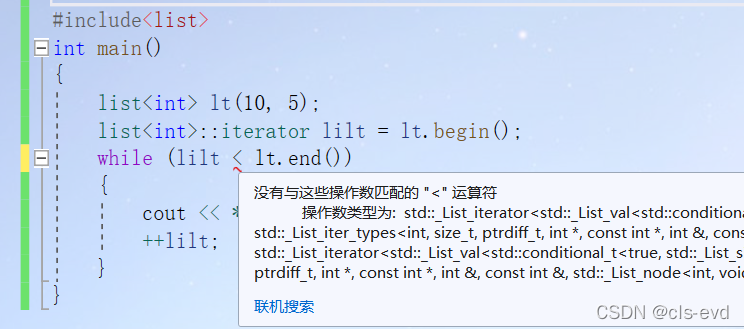
问题2:使用迭代器的时候是否能将 != 改为 ?
答案:对于string来说是可以的,因为它的底层就是数组,但是对于其他容器来讲就是不行的所以建议用 != ,不建议用>或者<. 以链表为例,对于链表来说后面的地址不一定比前面的地址大。

(5)const 迭代器
正向迭代器和反向迭代器都提供了const 版本,为什么呢?
为的就是提供给const对象是用。
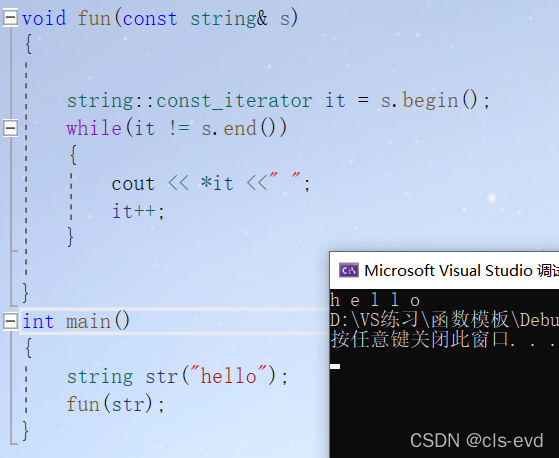
eg:对于下面这种函数

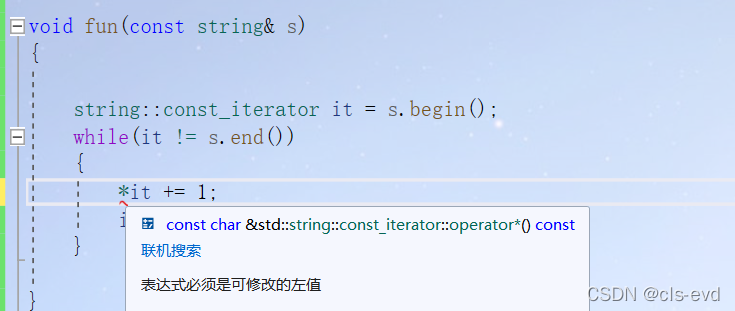
s是被const修饰的只能读不能改,如果用普通的迭代器,就会报错,const begin返回的是const_iterator而这里返回的却是iterator所以报错。
正确写法:
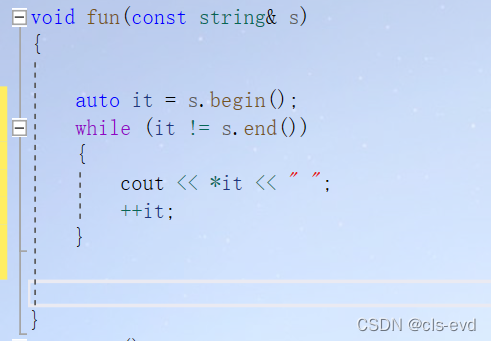
void fun(const string& s){string::const_iterator it = s.begin();while(it != s.end()){cout << *it <<" ";it++;}}int main(){string str("hello");fun(str);}
同样也不能对他进行修改了
同样可以写成auto让他自动推导
(6) at
功能和operator[]是一毛一样的.
int main(){string s1("hello world");for (size_t i = 0; i < s1.size(); i++) //读每个位置的字符{cout << s1.at(i) << " ";}cout << endl;for (size_t i = 0; i < s1.size(); i++) {s1.at(i)+= 1;}cout << endl;cout << s1 << endl;}
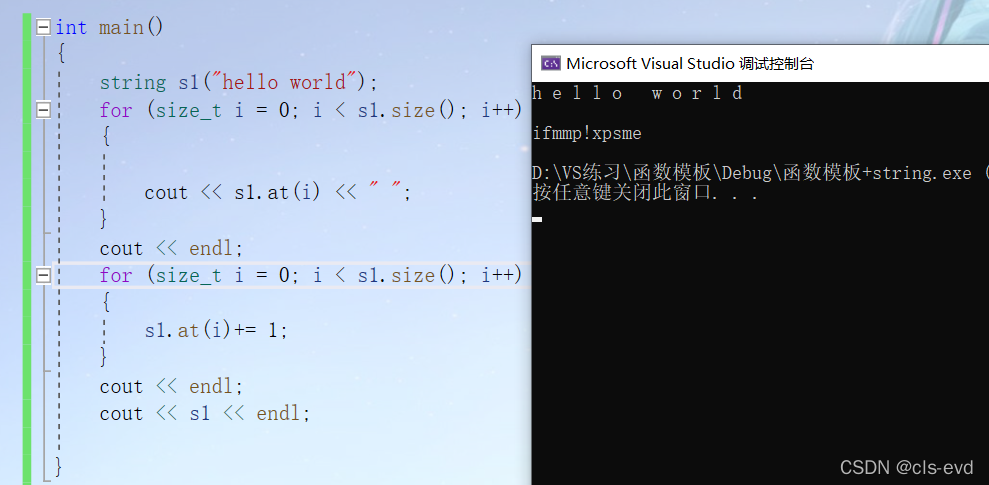
at与operator[ ]的区别
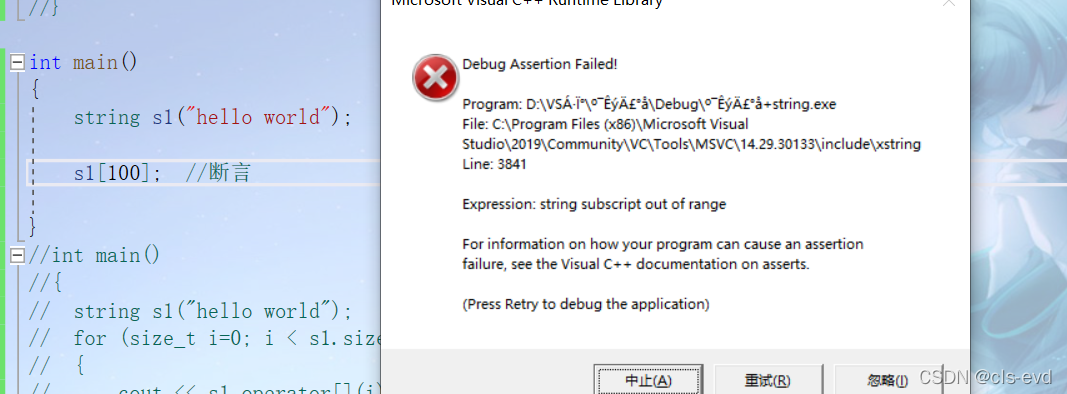
at与operator[ ] 的区别在于检查越界的方式不一样
operator[]检查异常的错误是断言。at检查错误的方式是抛异常,一般用operator []
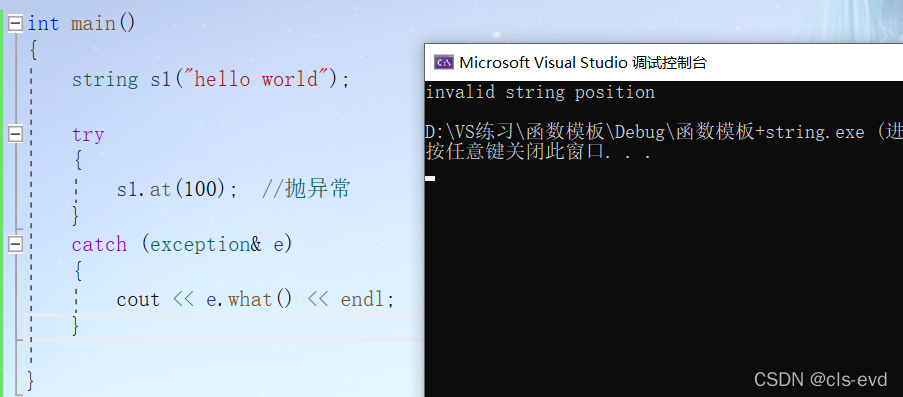
string类对象的修改操作

(1)插入字符
push_back 插入一个字符
append 插入字符串
+= 插入字符串或者插入一个完整字符
int main(){string s1;s1.push_back('a'); //插入一个字符s1.append("abcd");cout << s1 <<endl;s1 += ':';s1 += "hahahh";cout << s1 << endl; //插入直接推荐用+=,其他两个了解一下}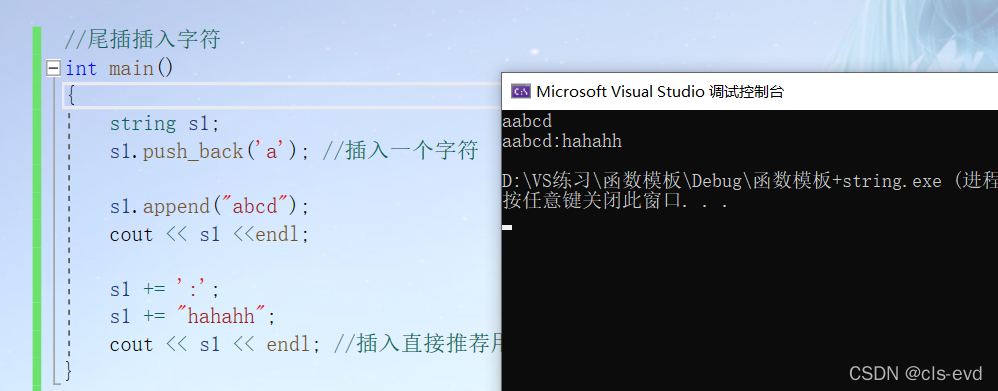
在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般 情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
(2) c_str
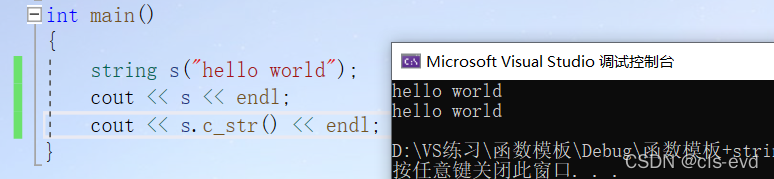
int main(){string s("hello world");cout << s << endl;cout << s.c_str() << endl;}
这两个s虽然输出结果一样但是意义不一样,c_str返回c格式的字符串
实际当中也很有意义:
- 要跟C库里面的函数结合,就用它。
- 假如有个file的字符串是用string来存的,想用C语言的形式打开一个文件
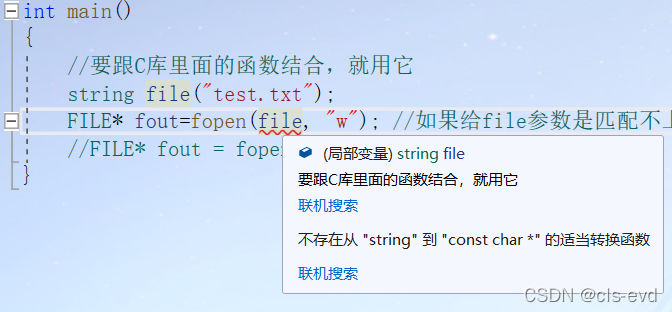
eg:打开文件
int main(){//要跟C库里面的函数结合,就用它string file("test.txt"); //假如有个file的字符串是用string来存的,想用C语言的形式打开一个文件//FILE* fout=fopen(file, "w"); //如果给file参数是匹配不上的,因为fopen的第一个参数必须是const char*FILE* fout = fopen(file.c_str(), "w");}
直接传是不行的,因为fopen的第一个参数必须是const char*。这时候借助c_str就行了

(3) find与rfind及substr
find 有以下四种重载
size_t find (const string& str, size_t pos = 0) const;size_t find (const char* s, size_t pos = 0) const;size_t find (const char* s, size_t pos, size_t n) const;size_t find (char c, size_t pos = 0) const;find判别方法:如果找到了,返回的是第一个找到这个字符的位置的下标,如果没找到返回的就是npos(42亿9千万的位置)取出找到的字符就要用到substr。
substr:从pos这个位置开始,取len个字符(len给npos的缺省值)
string substr (size_t pos = 0, size_t len = npos) const;
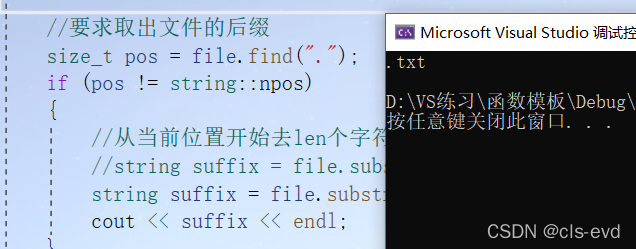
先介绍最后一个:比如说对上面这个file要求取出文件的后缀,先用find找到 . 再用substr提取出.后面的内容 。
int main(){string file("test.txt"); FILE* fout = fopen(file.c_str(), "w");//要求取出文件的后缀size_t pos = file.find(".");if (pos != string::npos){//从当前位置开始去len个字符串//string suffix = file.substr(pos,file.size()-pos);string suffix = file.substr(pos);cout << suffix << endl;}}
ps:长度计算原理
1.0 len=file.size()-pos;
2.0 当然也可以不用计算len,利用len的缺省值npos,自动把后面全取完


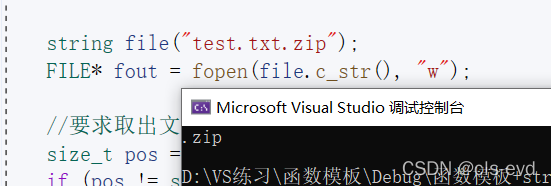
如果对于下面这段代码呢 ?具有连续后缀,find使用起来就相对困难,这时候就可以使用rfind进行倒着取(从右往左去找),用法与刚才类似。
int main(){string file("test.txt.zip");FILE* fout = fopen(file.c_str(), "w");//要求取出文件的后缀size_t pos = file.rfind(".");if (pos != string::npos){//从当前位置开始去len个字符串//string suffix = file.substr(pos,file.size()-pos);string suffix = file.substr(pos);cout << suffix << endl;}}
对于网址一般有三部分构成,协议/域名/统一资源定位假设要求要把这三个部分解析出来那又该怎么办呢?
就比如对博主博客的网址进行解析:

1.0 提取协议http或者https就叫做协议,所以找到带一个:即可
size_t pos1 = url.find(":");string protocol = url.substr(0, pos1 - 0);cout << protocol << endl;2.0 提取域名就要直到中间的斜杠/ ,这时候就要借助find的另一个功能,从指定位置开始查找
因为协议的格式是固定的,所以要从:后的第三个位置开始查找斜杠 /
size_t find (const string& str, size_t pos = 0) const;size_t pos2=url.find('/',pos1+3 );string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));cout << domain << endl;3.0 uri就是最后剩余的,比较简单,直接默认提取出全部字符串即可
string uri = url.substr(pos2+1);cout << uri << endl;
完整过程:int main(){string url("https://mp.csdn.net/mp_blog/creation/editor/123482486");//对于网址,协议/size_t pos1 = url.find(":");string protocol = url.substr(0, pos1 - 0);cout << protocol << endl;size_t pos2=url.find('/',pos1+3 );string domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));cout << domain << endl;string uri = url.substr(pos2+1);cout << uri << endl;}

(4)insert
不到万不得已,不建议使用,因为时间复杂度是O(N),效率太低
insert的三种重载
string& insert (size_t pos, size_t n, char c);iterator insert (iterator p, char c);string& insert (size_t pos, const string& str);
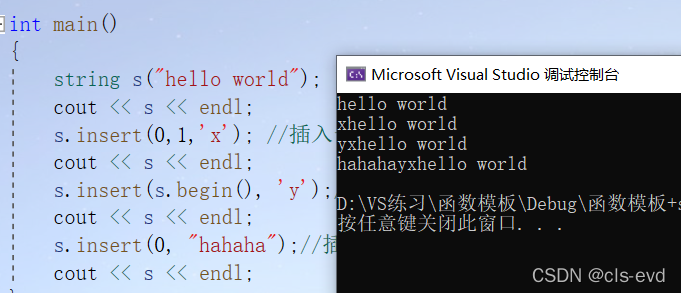
eg:头插
int main(){string s("hello world");cout << s << endl;s.insert(0,1,'x'); //插入一个字符cout << s << endl;s.insert(s.begin(), 'y');//插入一个字符,用迭代器cout << s << endl;s.insert(0, "hahaha");//插入一个字符串cout << s << endl;}
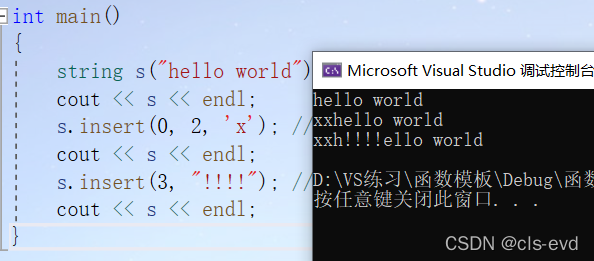
eg:从中间位置进行插入
int main(){string s("hello world");cout << s << endl;s.insert(0, 2, 'x'); //插入2个字符cout << s << endl;s.insert(3, "!!!!"); //从第3个位置插入字符串cout << s << endl;}
(5)erase
删除中间和头部位置同样不建议使用,因为效率低.
erase的函数定义
string& erase (size_t pos = 0, size_t len = npos);
eg:
int main(){string s("hello world");cout << s << endl;s.erase(0, 1); //将头上第一个字符删掉想cout << s << endl;s.erase(s.size() - 1, 1);cout << s << endl; //将尾部的一个字符删除s.erase(3); //保留了前三个字符。因为后面都删完了cout << s << endl;}
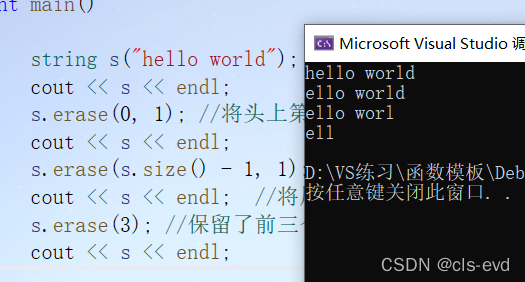
string类非成员函数
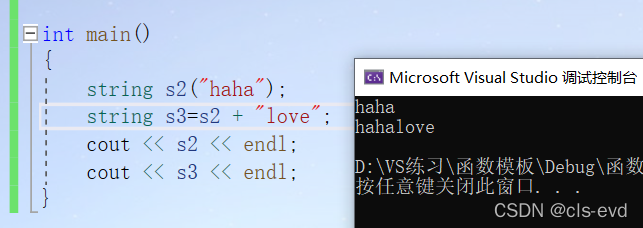
 (1)operator +
(1)operator +
与+=实现的功能相同,只不过+不会改变本身
PS:建议尽量少用,因为传值返回,导致深拷贝效率低
(2) 流提取和流插入
支持直接输入输出字符串
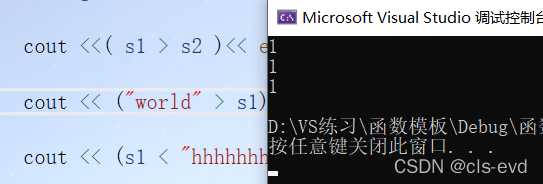
(3)比较大小
支持string与string比较,也支持自定义类型与string比较,如果是真返回1,如果是假返回0.
int main(){string s1("hello world");string s2("hello");cout < s2 )<< endl;cout < s1) << endl;cout << (s1 < "hhhhhhhh") << endl;}
实际中经常用的还是string与string比,剩下的不常用
(4)stoi(string to int)
功能:将字符串类型转成整形
stoi定义:给一个字符串将它转化成整形,后面两个参数不用管,我们用默认缺省即可
int stoi (const string& str, size_t* idx = 0, int base = 10);
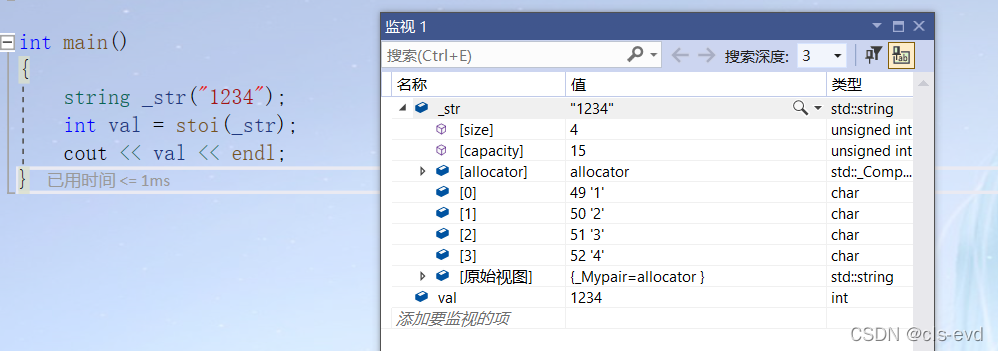
eg:
int main(){string _str("1234");int val = stoi(_str);cout << val << endl;}
(5)to_string
to_string定义(有多个重载)
功能:将整形,浮点型等等转成字符串
string to_string (int val);string to_string (long val);string to_string (long long val);string to_string (unsigned val);string to_string (unsigned long val);string to_string (unsigned long long val);string to_string (float val);string to_string (double val);string to_string (long double val);
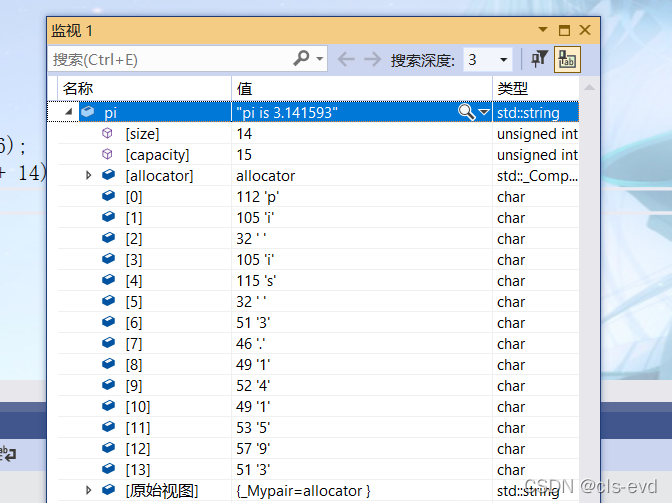
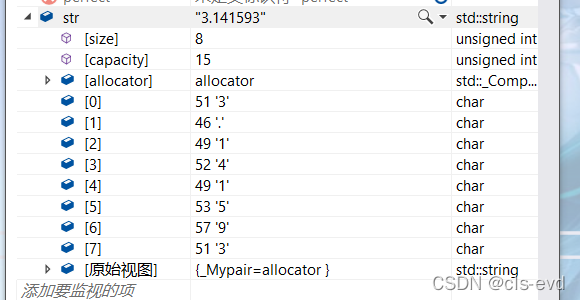
eg:
int main(){string pi = "pi is " + to_string(3.1415926);string str = to_string(3.1415926);cout << str << endl;cout << pi << '\n';return 0;}通过监视我们可以看出确实被准换成了字符串,ps:浮点型准换默认保留小数点后六位
(6)getline
功能:获取一行字符串,它的好处在于能接受到空格
getline定义:
istream& getline (istream& is, string& str, char delim);istream& getline (istream& is, string& str);
eg: getline可以接受空格
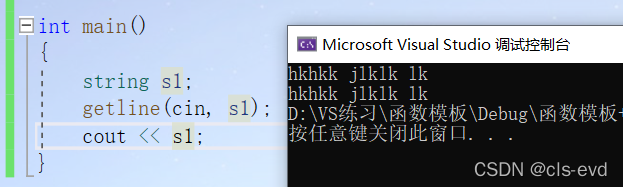
cin接受不了空格