机械转码日记【10】一文入门C++引用
目录
前言
1.引用的概念
2.引用的特性
2.1引用在定义时必须初始化
2.2一个变量可以有多个引用
2.3引用一旦引用一个实体,再不能引用其他实体
3.常引用
3.1引用后变量的访问权限只能缩小不能扩大
3.2常量也可以被引用
3.3常引用可以应用于类型转换
4.引用的使用场景
4.1引用做函数参数
4.1.1引用做函数参数可以减少拷贝提高效率
4.1.2引用传参不需要传地址,写起来更爽
4.2引用做函数返回值
4.2.1值返回并不是直接返回
4.2.2引用返回的是别名
4.2.3引用返回要注意的地方
5.引用和指针的区别
前言
这篇博客主要是介绍C++的引用,讲了引用的概念、引用的特性、常引用、引用的使用场景以及引用和指针的去边;新手创作者,欢迎大佬们指出不足!本篇博客的测试代码已经上传到了我的gitee了,有需要的老铁可以取用:C++引用
1.引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。它的用法是:
类型& 引用变量名(对象名) = 引用实体
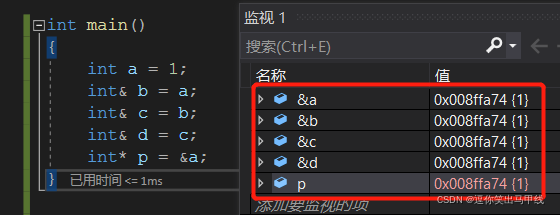
可以看到定义的a的引用别名b,c,d后,他们的地址都与a相同,也与a的指针所存储的a的地址相同,说明引用并不是定义了新的变量,而是给已存在的变量取了一个别名 。
2.引用的特性
引用有三个特性:
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
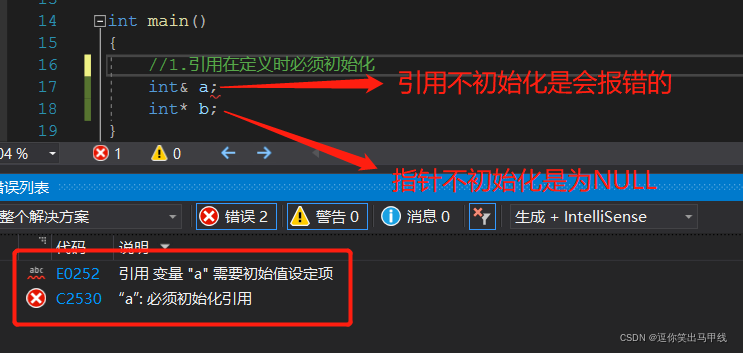
2.1引用在定义时必须初始化
可能你会觉得引用和指针有点像,但是指针可以不进行初始化,引用不能不进行初始化。
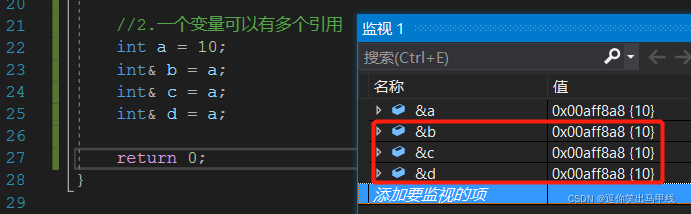
2.2一个变量可以有多个引用
你可以理解为引用是给别人取外号,一个人的外号也可以有很多个。
2.3引用一旦引用一个实体,再不能引用其他实体
引用是专情的,只要认了主,就不会改变为别的变量的引用

3.常引用
其实引用也可以用const修饰,用法如下:
const 类型& 引用变量名(对象名) = 引用实体
那么常引用又会有那些地方需要注意呢?
3.1引用后变量的访问权限只能缩小不能扩大
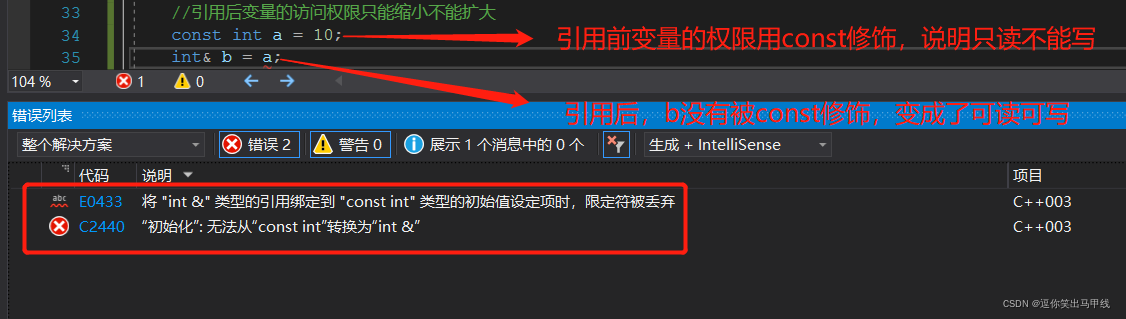
如上图,引用后,变量的访问权限从只读变成了可读可写,说明访问权限扩大了,这时编译器会报错。那么如何改变这个错误呢,只需要将int& b = a改变为const int& b = a即可:
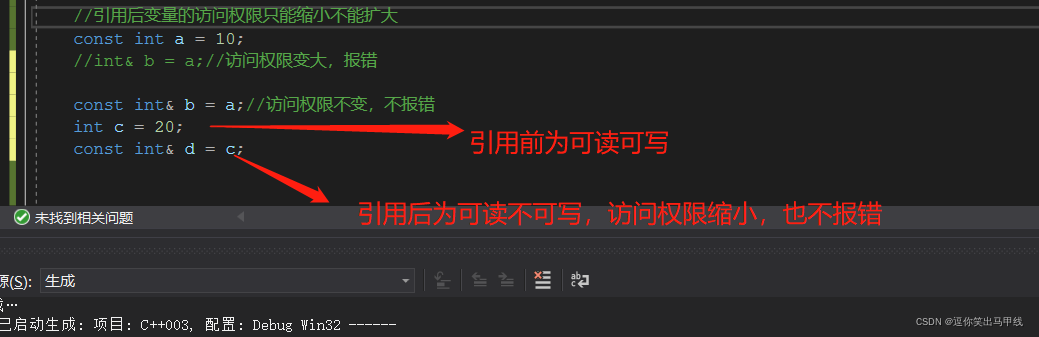
上图说明,访问权限缩小和不变都不会报错,只有当访问权限扩大时才会报错。
3.2常量也可以被引用
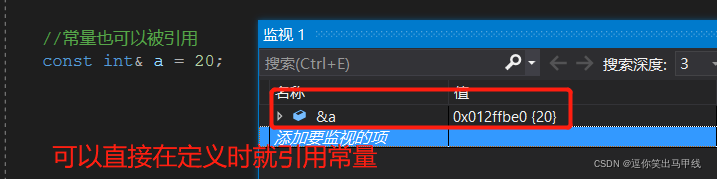
引用在用const修饰之后,可以在定义时就引用一个常量。
3.3常引用可以应用于类型转换
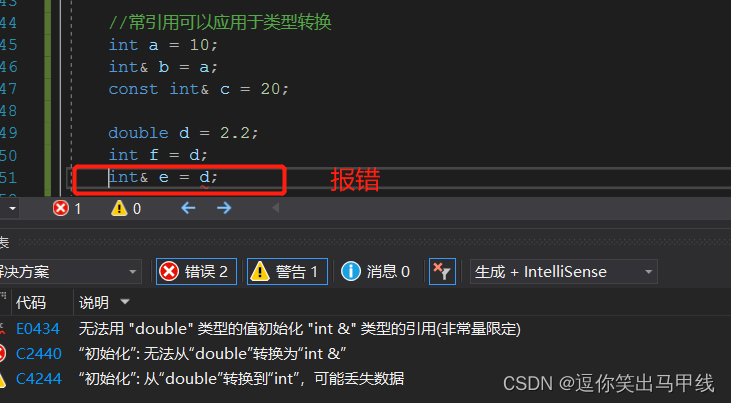
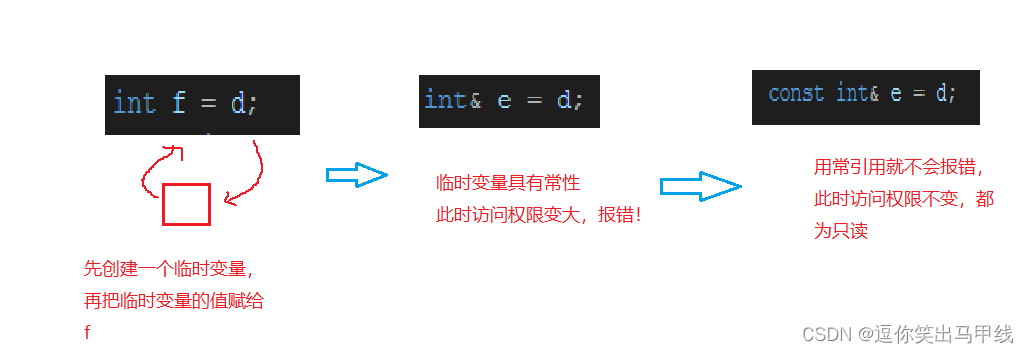
为什么以上程序会报错呢?是因为int类型的引用不能引用double类型的吗?那下面我们再改动一下代码:
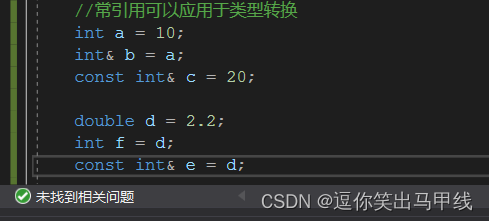
当我们用了常引用之后,发现程序不报错了,这是为什么呢?其实在类型转换中,并不是直接转换,以double类型变为int类型为例,这里是把double类型的整数部分存到一个临时变量中,再把临时变量中的值拷贝给f,而临时变量具有常性,用int&e不能接收,相当于访问权限变大了,所以用const常引用可以接收。
4.引用的使用场景
引用有两种使用场景:
- 引用做函数参数
- 引用做函数返回值
4.1引用做函数参数
引用作为函数的参数,有两点好处:
- 减少拷贝,提高效率
- 不需要传地址,写起来也很爽
4.1.1引用做函数参数可以减少拷贝提高效率
与传值相比,引用作为函数的参数效率提高了很多。传值的时候,因为在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。下面我们用代码来看看传值和传引用的效率:
#include struct A { int a[10000]; };void TestFunc1(A a) {}void TestFunc2(A& a) {}void TestRefAndValue(){A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;}int main(){TestRefAndValue();}运行结果为:

可见传引用效率比传值高了很多。
4.1.2引用传参不需要传地址,写起来更爽
//引用做函数参数void swap(int& a, int& b){int tmp = a;a = b;b = tmp;}//如果换成指针void swap(int* a, int* b){int tmp = *a;*a = *b;*b = tmp;}int main(){int a = 6;int b = 88;swap(a, b);cout << a << endl;cout << b << endl;swap(&a, &b);cout << a << endl;cout << b << endl;return 0;}与传指针相比,函数定义的时候不需要写解应用,函数使用的时候也不需要传地址,这减少了我们的代码量,看起来更加的清爽。
4.2引用做函数返回值
值和引用的作为返回值类型,他们的效率也不相同,引用作为返回值类型要比值作为返回值类型的效率要高。我们先用代码来测试一下:
//引用作为函数返回值#include struct A { int a[10000]; };A a;// 值返回A TestFunc1() { return a; }// 引用返回A& TestFunc2() { return a; }void TestReturnByRefOrValue(){// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;}int main(){TestReturnByRefOrValue();}结果为:

为什么他们的效率会相差这么大呢,因为如果函数是值返回,一般是将这个数据先存到一个临时的区域里(比如寄存器),然后将寄存器的值再赋给函数调用后接收返回值的那个变量,寄存器的读和写都需要时间,所以效率较低;而引用作为返回值,就没有拷贝的这个过程了,而是直接将返回的值取一个别名赋给函数调用后接收返回值的那个变量。
4.2.1值返回并不是直接返回
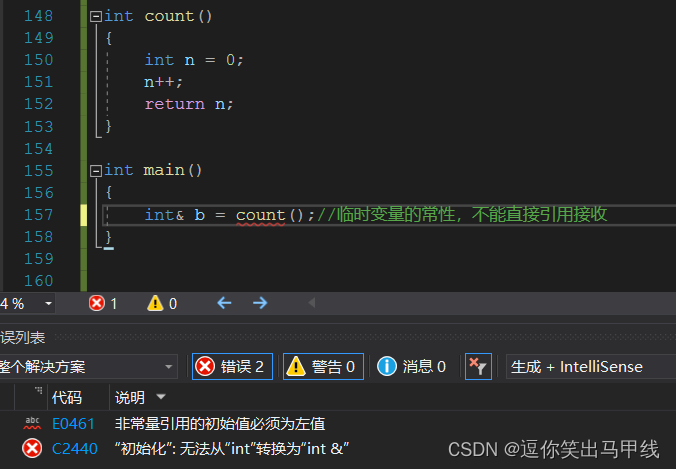
以上代码就可以看出值引用并不是直接返回这个值,而是先储存到一个临时变量中,再把临时变量的值赋给接收返回值的变量。变为常引用就可以接收了:
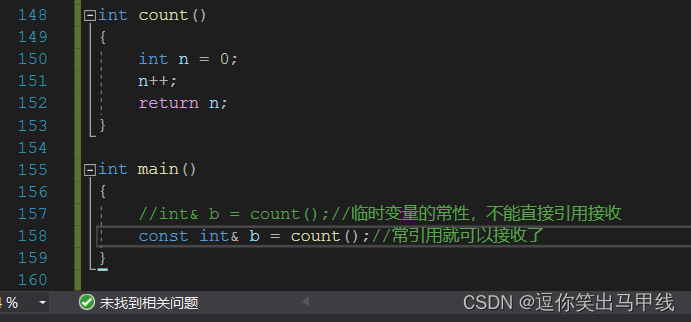
4.2.2引用返回的是别名
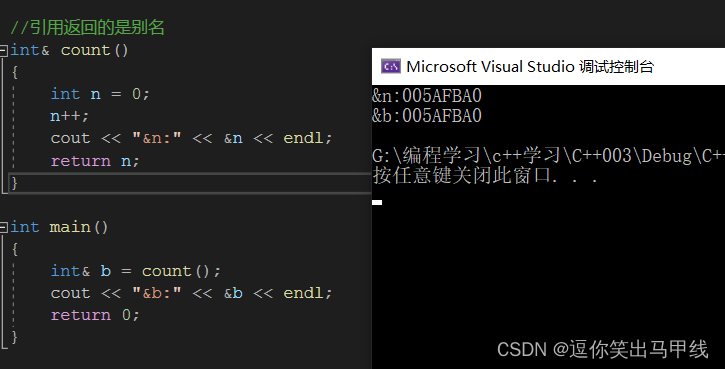
可以看到当我们用引用作为函数返回值的时候,直接使用int&类型去接收也是可以的,不需要转变为常引用,说明当引用作为函数返回值的时候,并没有产生临时变量,直接返回这个变量的别名,可以看到我们的输出地址是完全一样的,说明确实是别名。
4.2.3引用返回要注意的地方
注意:如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。比如刚刚我们的代码:
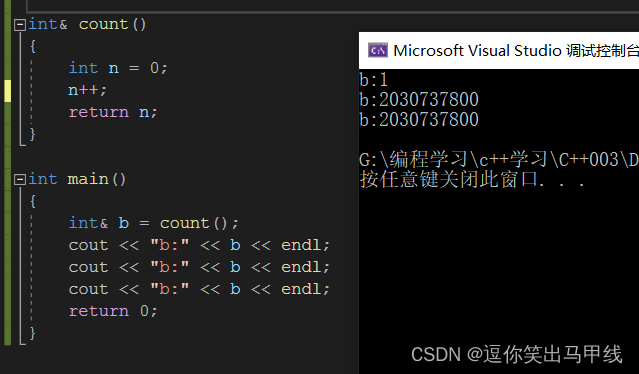
可以看到我们的程序只有第一次是输出1的,第二次和第三次输出的都是随机值,这是为什么呢?因为n是函数内部的局部变量,这个变量的作用域只是这个count函数,函数调用过后,这个函数所占用的运行空间就被还给操作系统了,这块空间可以被覆盖,这个时候,我们b的地址储存的就不是1了,而是随机值,甚至连第一次输出1也是巧合,这和编译器有关。(举个小例子,函数调用时所占用的那块内存相当于酒店的房间,返回的引用相当于酒店的房卡,函数调用完就相当于我们退房了,虽然我们退房了,但是酒店的房间仍然存在,我们拿原先的那张房卡虽然仍然可以访问这间房间,但是里面躺的确是别人了,我们拿这张房卡去开别人的房门那也算是非法访问内存了,是一种错误)那我们应该如何改进呢:
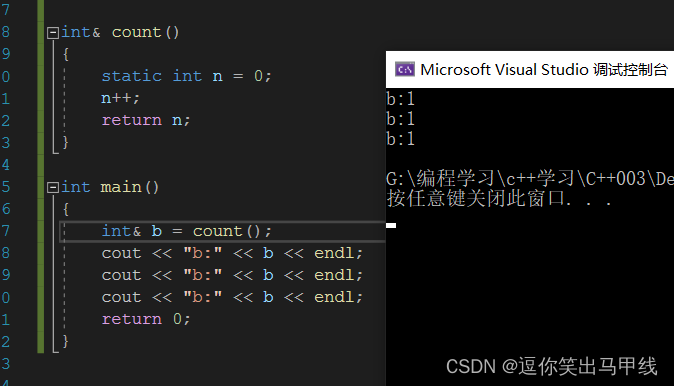
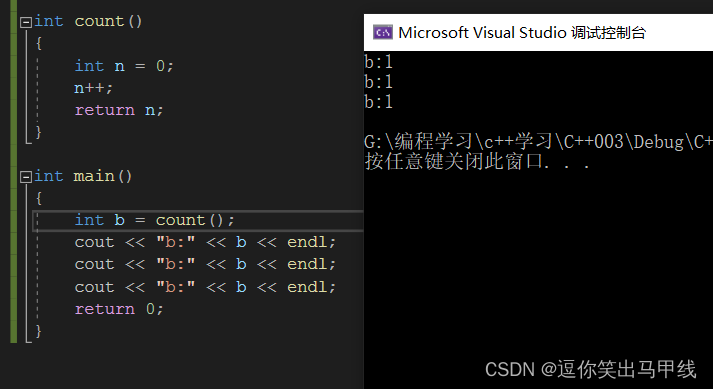
加一个static可以解决这个问题,可以让n的生命周期延长(n放在静态区了,函数栈帧在栈区,n不会被覆盖),即虽然count的这块空间可以被覆盖,但是b的这块空间在main函数结束之前都不会被覆盖。(但实际上还是不建议这么做的,因为static有关系到线程安全的问题,这个现在还挺复杂,我们后面再讲),所以还是下面的传值比较好:
5.引用和指针的区别
- 在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。指针在语法角度而言,指针存储了变量的地址,开辟了4/8byte空间。
- 从底层的角度来说,他们实现的方式是一样的,在底层实现上引用实际是有空间的,因为引用是按照指针方式来实现的。
如下面这段代码:
int main(){int a = 10;// 语法角度而言:ra是a的别名,没有额外开空间// 底层的角度:他们是一样的方式实现的int& ra = a;ra = 20;// 语法角度而言:pa存储a的地址,pa开了4/8byte空间// 底层的角度:他们是一样的方式实现的int* pa = &a;*pa = 20;return 0;}在调试模式下转到反汇编查看汇编代码:
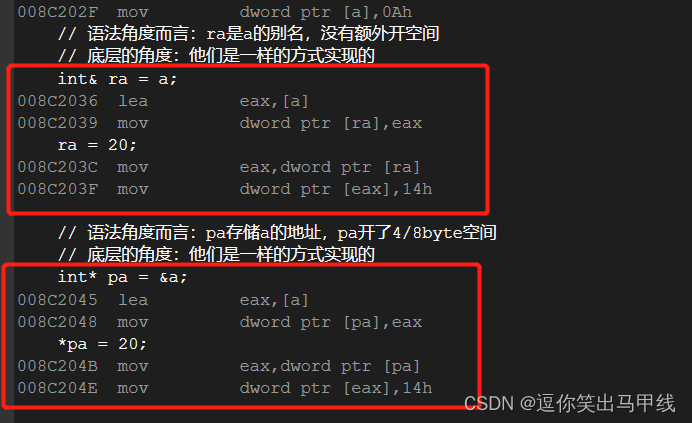
可以看到他们的汇编代码的实现逻辑都是一样的,所以他们的底层实现方式都是一样的。
引用和指针的不同点:
- 引用在定义时必须初始化,指针没有要求。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
- 没有NULL引用,但有NULL指针。
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)。
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
- 有多级指针,但是没有多级引用。
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
- 引用比指针使用起来相对更安全。
 2022深度学习开发者峰会
2022深度学习开发者峰会  5月20日13:00让我们相聚云端,共襄盛会!
5月20日13:00让我们相聚云端,共襄盛会!

