ZooKeeper系列-存储原理-事务日志/快照文件介绍
standalone模式下ZooKeeper处理写请求流程分析
一.Zookeeper请求处理流程

大致说下各个类的作用:
- CnxnChannelHandler: netty的ChannelHandler ,用来处理zookeeper的连接、数据读取,
- NettyServerCnxn: 该类代表了一个客户端连接,每当一个新的连接建立,zookeeper服务端就会创建一个NettyServerCnxn,用于处理连接的数据
- ZooKeeperServer:代表一个单机zookeeper实例,用于时处理客户端请求的入口,在这里将客客户端信息,封装成Request,供后面流程使用
- 三个RequestProcessor
- PrepRequestProcessor:设置事务信息、校验信息、将request信息转化成ChangeRecord,保存到ZooKeeperServer的outstandingChanges队列中.,并根据不同的操作,生成不同的Txn,一个txn是Record的实现类,里面包含当前操作节点的信息
- SyncRequestProcessor:主要用于刷新当前事务日志到磁盘和创建新的日志文件、生成快照信息,下面会重点讲解
- FinalRequestProcessor:当前取出待编程的ChangeRecord,进行操作,因为这些ChangeRecord都是写操作,所以会完成节点的新增、删除、数据更新,然后设置返回结果
- ZKDatabase:对DataTree和事务日志、快照操作的统一封装,提供统一接口
- DataTree:ZooKeeper内存数据结构的实现,持有zookeeper当前所有的节点信息(持久节点、临时节点各种类型)、watcher信息
二、ZooKeeper数据存储原理
2.1.ZooKeeper数据存储结构
虽然Zookeeper采用的是文件系统存储机制,但是所有的数据都会被加载到内存中,当用于读取、操作数据或节点时,都会直接操作内存中的数据.但是操作记录会以事务日志的记录下来,大概结构如下:
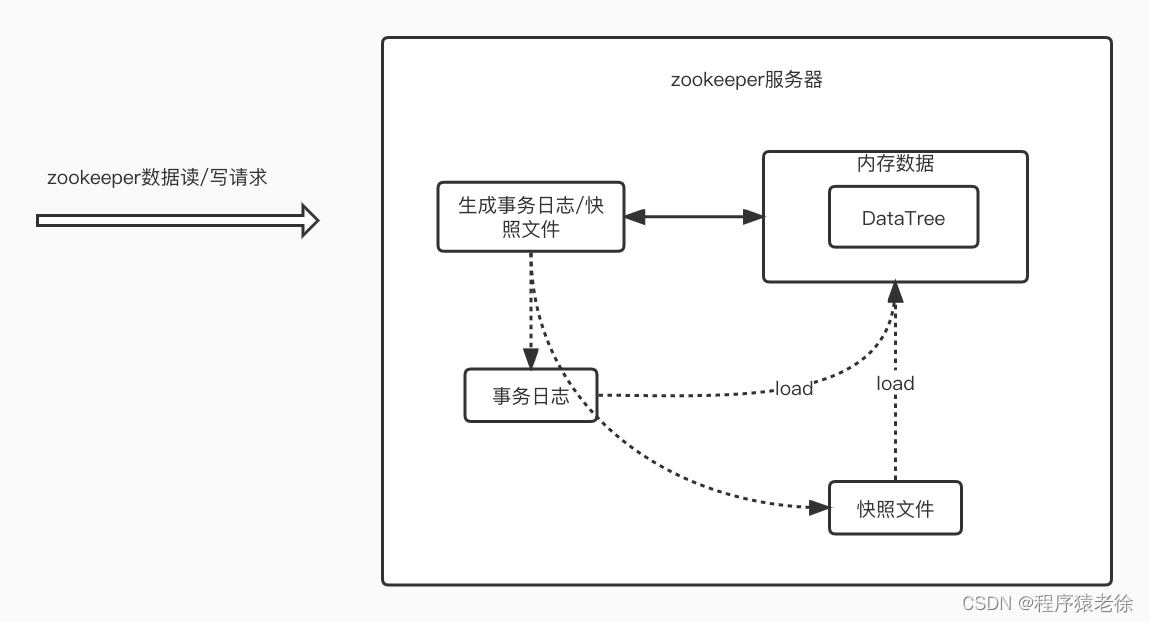
大致工作原理如下:
- 当zookeeper启动时,会从快照文件和事务日志里面恢复数据,加载到内存中,形成DataTree,即ZooKeeper树形数据结构
- 当ZooKeeper处理读请求时,会直接根据path从内存中获取数据,不生成事务日志
- 当ZooKeeper处理写请求时,会生成对应的事务日志,并操作对应的DataTree
- ZooKeeper会按照一定请求次数来生成新的事务日志文件和生成新的快照文件
2.2.ZooKeeper的内存数据结构DataTree
我们先来看下DataTree的源码
public class DataTree { private static final Logger LOG = LoggerFactory.getLogger(DataTree.class); /** * This hashtable provides a fast lookup to the datanodes. The tree is the * source of truth and is where all the locking occurs */ private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>(); private final WatchManager dataWatches = new WatchManager(); private final WatchManager childWatches = new WatchManager(); /** the root of zookeeper tree */ private static final String rootZookeeper = "/"; /** the zookeeper nodes that acts as the management and status node **/ private static final String procZookeeper = Quotas.procZookeeper; /** this will be the string thats stored as a child of root */ private static final String procChildZookeeper = procZookeeper.substring(1); /** * the zookeeper quota node that acts as the quota management node for * zookeeper */ private static final String quotaZookeeper = Quotas.quotaZookeeper; /** this will be the string thats stored as a child of /zookeeper */ private static final String quotaChildZookeeper = quotaZookeeper .substring(procZookeeper.length() + 1); /** * the zookeeper config node that acts as the config management node for * zookeeper */ private static final String configZookeeper = ZooDefs.CONFIG_NODE; /** this will be the string thats stored as a child of /zookeeper */ private static final String configChildZookeeper = configZookeeper .substring(procZookeeper.length() + 1); /** * the path trie that keeps track fo the quota nodes in this datatree */ private final PathTrie pTrie = new PathTrie(); /** * This hashtable lists the paths of the ephemeral nodes of a session. */ private final Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>(); /** * This set contains the paths of all container nodes */ private final Set<String> containers = Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>()); /** * This set contains the paths of all ttl nodes */ private final Set<String> ttls = Collections.newSetFromMap(new ConcurrentHashMap<String, Boolean>());}上面显示了DataTree中所包含的信息,我们下面来挨个介绍下:
- ConcurrentHashMap nodes:节点信息,key为节点路径,DataNode为节点信息,包含当前节点的数据信息、统计信息、子节点列表
- WatchManager dataWatches:当前DataTree节点的watcher集合,主要包括两部分内容
- HashMap watchTable:根据path查找对应的watcher结合,
- HashMap watch2Paths:根据watcher查找关联了哪些节点
- WatchManager childWatches:监控子节点的watcher结合,数据结构和dataWatches相同
- PathTrie pTrie:维护了当前DataTree中所有的路径信息,如/root,/root/children,
- Map ephemerals:维护了当前DataTree中所有的临时节点信息
- 当前session 对应的临时节点的路径集合
- Set containers:当前DataTree中container类型节点的路径集合
- Set ttls: 当前DataTree中ttl类型节点的路径集合
- ReferenceCountedACLCache aclCache: ACL信息缓存
我们从源码可以看出DataTree的内部存储实际就是一个Map,
ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();Key:当前path
value: DataNode
我们看下DataNode:
public class DataNode implements Record { /** the data for this datanode */ byte data[]; /** * the acl map long for this datanode. the datatree has the map */ Long acl; /** * the stat for this node that is persisted to disk. */ public StatPersisted stat; /** * the list of children for this node. note that the list of children string * does not contain the parent path -- just the last part of the path. This * should be synchronized on except deserializing (for speed up issues). */ private Set<String> children = null; }DataNode是Record的一个实现,里面主要包括:
- data[]:当前node的数据
- acl:当前node的acl值
- stat:当前node的统计信息
- Children:当前node的子节点
Record接口:
@InterfaceAudience.Publicpublic interface Record { public void serialize(OutputArchive archive, String tag) throws IOException; public void deserialize(InputArchive archive, String tag) throws IOException;}Record接口是ZooKeeper内部定义的序列化与反序列的接口,所有需要参与序列化的都需要实现该接口.在ZooKeeper内部有以下几种类型实现该接口:
- xxRequest\xxResponse: ZooKeeper请求和响应数据实体
- xxTxn: 代表事务日志的实体
- ACL: acl权限信息实体类
- DataNode: ZooKeeper节点实体类
- Stat: 节点的统计信息
- LearnerInfo 选举过程的群首信息
- FileHeader: 事务日志,头部信息实体类
- 等
我们下面来分析下,zookeeper中创建节点的具体流程,其中也看下三个重要的RequestProcessor.
2.2.1.创建节点
2.2.1.1.创建节点的流程
2.2.1.1.1.PrepRequestProcessor
public class PrepRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor{ LinkedBlockingQueue<Request> submittedRequests = new LinkedBlockingQueue<Request>(); private final RequestProcessor nextProcessor; //1.收到请求,添加到待处理队列 public void processRequest(Request request) { submittedRequests.add(request); } @Override public void run() { while (true) { Request request = submittedRequests.take(); ... //处理请求 pRequest(request); ... } } protected void pRequest(Request request) throws RequestProcessorException { // LOG.info("Prep>>> cxid = " + request.cxid + " type = " + // request.type + " id = 0x" + Long.toHexString(request.sessionId)); request.setHdr(null); request.setTxn(null); switch (request.type){ case OpCode.createContainer: case OpCode.create: case OpCode.create2: //new 一个CreateRequest CreateRequest create2Request = new CreateRequest(); pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true); break; ... } request.zxid = zks.getZxid(); nextProcessor.processRequest(request); } protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException { request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid, Time.currentWallTime(), type)); switch (type) { case OpCode.create: case OpCode.create2: case OpCode.createTTL: case OpCode.createContainer: { pRequest2TxnCreate(type, request, record, deserialize); break; } ... } } //将进行数据、权限校验,设置request的txn(事务日志信息),然后生成ChangeRecord,添加到zks.outstandingChanges中, private void pRequest2TxnCreate(int type, Request request, Record record, boolean deserialize) throws IOException, KeeperException { if (deserialize) { ByteBufferInputStream.byteBuffer2Record(request.request, record); } int flags; String path; List<ACL> acl; byte[] data; long ttl; if (type == OpCode.createTTL) { CreateTTLRequest createTtlRequest = (CreateTTLRequest)record; flags = createTtlRequest.getFlags(); path = createTtlRequest.getPath(); acl = createTtlRequest.getAcl(); data = createTtlRequest.getData(); ttl = createTtlRequest.getTtl(); } else { CreateRequest createRequest = (CreateRequest)record; flags = createRequest.getFlags(); path = createRequest.getPath(); acl = createRequest.getAcl(); data = createRequest.getData(); ttl = -1; } CreateMode createMode = CreateMode.fromFlag(flags); validateCreateRequest(path, createMode, request, ttl); String parentPath = validatePathForCreate(path, request.sessionId); List<ACL> listACL = fixupACL(path, request.authInfo, acl); ChangeRecord parentRecord = getRecordForPath(parentPath); checkACL(zks, parentRecord.acl, ZooDefs.Perms.CREATE, request.authInfo); int parentCVersion = parentRecord.stat.getCversion(); if (createMode.isSequential()) { path = path + String.format(Locale.ENGLISH, "%010d", parentCVersion); } validatePath(path, request.sessionId); try { if (getRecordForPath(path) != null) { throw new KeeperException.NodeExistsException(path); } } catch (KeeperException.NoNodeException e) { // ignore this one } boolean ephemeralParent = EphemeralType.get(parentRecord.stat.getEphemeralOwner()) == EphemeralType.NORMAL; if (ephemeralParent) { throw new KeeperException.NoChildrenForEphemeralsException(path); } int newCversion = parentRecord.stat.getCversion()+1; if (type == OpCode.createContainer) { request.setTxn(new CreateContainerTxn(path, data, listACL, newCversion)); } else if (type == OpCode.createTTL) { request.setTxn(new CreateTTLTxn(path, data, listACL, newCversion, ttl)); } else { request.setTxn(new CreateTxn(path, data, listACL, createMode.isEphemeral(), newCversion)); } StatPersisted s = new StatPersisted(); if (createMode.isEphemeral()) { s.setEphemeralOwner(request.sessionId); } parentRecord = parentRecord.duplicate(request.getHdr().getZxid()); parentRecord.childCount++; parentRecord.stat.setCversion(newCversion); addChangeRecord(parentRecord); addChangeRecord(new ChangeRecord(request.getHdr().getZxid(), path, s, 0, listACL)); } private void addChangeRecord(ChangeRecord c) { synchronized (zks.outstandingChanges) { zks.outstandingChanges.add(c); zks.outstandingChangesForPath.put(c.path, c); } }} 总结一下,PrepRequestProcessor做了哪些事情:
- 将用户的create节点相关数据,转化为一个ChangeRecord,存放到zks.outstandingChanges队列中,会在FinalRequestProcessor中被处理.
- 生成请求的事务日志信息txn,会被后面的SyncRequestProcessor处理
我们SyncRequestProcessor先不重点分析,在下面的事务日志章节里面会有分析,我们需要知道的是,zookeeper在这一步会生成事务日志.
接下来我们来看FinalRequestProcessor
2.2.1.1.2.FinalRequestProcessor
从名字来看,这是最后一个RequestProcessor,
public class FinalRequestProcessor implements RequestProcessor { private static final Logger LOG = LoggerFactory.getLogger(FinalRequestProcessor.class); ZooKeeperServer zks; public void processRequest(Request request) { //1.从zks.outstandingChanges中取出请求,并处理 //2.根据请求类型,来处理请求,并生成对应的response信息 //3.调用ServerCnxn接口,发送Response信息}}outstandingChanges
synchronized (zks.outstandingChanges) { // Need to process local session requests rc = zks.processTxn(request); // request.hdr is set for write requests, which are the only ones // that add to outstandingChanges. if (request.getHdr() != null) { TxnHeader hdr = request.getHdr(); Record txn = request.getTxn(); long zxid = hdr.getZxid(); while (!zks.outstandingChanges.isEmpty() && zks.outstandingChanges.peek().zxid <= zxid) { ChangeRecord cr = zks.outstandingChanges.remove(); if (cr.zxid < zxid) { LOG.warn("Zxid outstanding " + cr.zxid + " is less than current " + zxid); } if (zks.outstandingChangesForPath.get(cr.path) == cr) { zks.outstandingChangesForPath.remove(cr.path); } } }我们看下这块逻辑:
获取outstandingChanges->处理事务请求-> 从outstandingChanges中移除请求
处理事务请求关键代码:
rc = zks.processTxn(request);我们看下zks是怎么处理的?
public ProcessTxnResult processTxn(Request request) { return processTxn(request, request.getHdr(), request.getTxn()); }private ProcessTxnResult processTxn(Request request, TxnHeader hdr, Record txn) { ProcessTxnResult rc; int opCode = request != null ? request.type : hdr.getType(); long sessionId = request != null ? request.sessionId : hdr.getClientId(); if (hdr != null) { rc = getZKDatabase().processTxn(hdr, txn); } else { rc = new ProcessTxnResult(); } if (opCode == OpCode.createSession) { if (hdr != null && txn instanceof CreateSessionTxn) { CreateSessionTxn cst = (CreateSessionTxn) txn; sessionTracker.addGlobalSession(sessionId, cst.getTimeOut()); } else if (request != null && request.isLocalSession()) { request.request.rewind(); int timeout = request.request.getInt(); request.request.rewind(); sessionTracker.addSession(request.sessionId, timeout); } else { LOG.warn("*****>>>>> Got " + txn.getClass() + " " + txn.toString()); } } else if (opCode == OpCode.closeSession) { sessionTracker.removeSession(sessionId); } return rc; }我们看到在ZooKeeperServer(zks).processTxn的方法中,对request的hdr,即:事务信息进行判断,如果没有,说明档期不是写请求,只直接返回一个ProcessTxnResult结果.
如果是事务请求,则交由ZKDatabase处理:
public ProcessTxnResult processTxn(TxnHeader hdr, Record txn) { return dataTree.processTxn(hdr, txn); }而在ZKDatabase中,由交给了dataTree处理:
public ProcessTxnResult processTxn(TxnHeader header, Record txn) { return this.processTxn(header, txn, false); }public ProcessTxnResult processTxn(TxnHeader header, Record txn, boolean isSubTxn) { ProcessTxnResult rc = new ProcessTxnResult(); try { rc.clientId = header.getClientId(); rc.cxid = header.getCxid(); rc.zxid = header.getZxid(); rc.type = header.getType(); rc.err = 0; rc.multiResult = null; switch (header.getType()) { case OpCode.create: CreateTxn createTxn = (CreateTxn) txn; rc.path = createTxn.getPath(); //创建节点 createNode(createTxn.getPath(),createTxn.getData(),createTxn.getAcl(),createTxn.getEphemeral() ? header.getClientId() : 0,createTxn.getParentCVersion(),header.getZxid(), header.getTime(), null); break; ...} }catch(){ } }创建节点的函数:
public void createNode(final String path, byte data[], List<ACL> acl, long ephemeralOwner, int parentCVersion, long zxid, long time, Stat outputStat) throws KeeperException.NoNodeException, KeeperException.NodeExistsException { int lastSlash = path.lastIndexOf('/'); String parentName = path.substring(0, lastSlash); String childName = path.substring(lastSlash + 1); StatPersisted stat = new StatPersisted(); stat.setCtime(time); stat.setMtime(time); stat.setCzxid(zxid); stat.setMzxid(zxid); stat.setPzxid(zxid); stat.setVersion(0); stat.setAversion(0); stat.setEphemeralOwner(ephemeralOwner); DataNode parent = nodes.get(parentName); if (parent == null) { throw new KeeperException.NoNodeException(); } synchronized (parent) { Set<String> children = parent.getChildren(); if (children.contains(childName)) { throw new KeeperException.NodeExistsException(); } if (parentCVersion == -1) { parentCVersion = parent.stat.getCversion(); parentCVersion++; } parent.stat.setCversion(parentCVersion); parent.stat.setPzxid(zxid); Long longval = aclCache.convertAcls(acl); DataNode child = new DataNode(data, longval, stat); parent.addChild(childName); nodes.put(path, child); EphemeralType ephemeralType = EphemeralType.get(ephemeralOwner); if (ephemeralType == EphemeralType.CONTAINER) { containers.add(path); } else if (ephemeralType == EphemeralType.TTL) { ttls.add(path); } else if (ephemeralOwner != 0) { HashSet<String> list = ephemerals.get(ephemeralOwner); if (list == null) { list = new HashSet<String>(); ephemerals.put(ephemeralOwner, list); } synchronized (list) { list.add(path); } } if (outputStat != null) { child.copyStat(outputStat); } } // now check if its one of the zookeeper node child if (parentName.startsWith(quotaZookeeper)) { // now check if its the limit node if (Quotas.limitNode.equals(childName)) { // this is the limit node // get the parent and add it to the trie pTrie.addPath(parentName.substring(quotaZookeeper.length())); } if (Quotas.statNode.equals(childName)) { updateQuotaForPath(parentName .substring(quotaZookeeper.length())); } } // also check to update the quotas for this node String lastPrefix = getMaxPrefixWithQuota(path); if(lastPrefix != null) { // ok we have some match and need to update updateCount(lastPrefix, 1); updateBytes(lastPrefix, data == null ? 0 : data.length); } dataWatches.triggerWatch(path, Event.EventType.NodeCreated); childWatches.triggerWatch(parentName.equals("") ? "/" : parentName, Event.EventType.NodeChildrenChanged); }我们看下ZooKeeper创建节点时都做了什么:
- 设置节点的统计信息:StatPersisted stat
- 更新父节点的统计信息
- 生成一个DataNode,放到nodes里面,即新生成了一个节点
- 判断节点类型是否是:CONTAINER、TTL、临时节点中的一种
- 如果是加入对应的集合,我们前面提到过
- 更新配额信息
- 触发当前节点的watcher和所属父节点的children watcher
到此,我们完成了新增节点的处理流程梳理.
2.3.ZooKeeper事务日志
我们前面的流程中说到,zookeeper在处理写请求时,会生成事务日志,并会flush到磁盘中,接下我们看下zookeeper是如何实现的?
在正式的代码梳理前,我们思考以下几个问题,看能否在代码中找到答案?
- 事务日志文件的大小? 事务日志是一个大文件,还是多个小文件?如果是,切分条件是什么?
- 事务日志的内容什么格式?
- 事务日志是flush到磁盘的条件是什么?是每生成一条就flush一次,还是多条一起flush? 如果是多条,那么如何保证flush成功
2.3.1.源码梳理
接下来我们看下源码:
SyncRequestProcessor
public class SyncRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor { private Thread snapInProcess = null; private final LinkedList<Request> toFlush = new LinkedList<Request>(); /** * The number of log entries to log before starting a snapshot */ private static int snapCount = ZooKeeperServer.getSnapCount(); public void processRequest(Request request) { // request.addRQRec(">sync"); queuedRequests.add(request); } @Override public void run() { int logCount = 0; // we do this in an attempt to ensure that not all of the servers // in the ensemble take a snapshot at the same time int randRoll = r.nextInt(snapCount/2); while (true) { //1.获取要处理的request Request si = null; if (toFlush.isEmpty()) { si = queuedRequests.take(); } else { si = queuedRequests.poll(); if (si == null) {flush(toFlush);continue; } } if (si == requestOfDeath) { break; } /***下面的逻辑主要包括三部分 1.判断是否生成新的事务文件 2.判断是否进行快照生成 3.是否将事务信息 按group 进行flush到磁盘,即事务文件 ***/ if (si != null) { // track the number of records written to the log if (zks.getZKDatabase().append(si)) { logCount++; if (logCount > (snapCount / 2 + randRoll)) {randRoll = r.nextInt(snapCount/2);// roll the logzks.getZKDatabase().rollLog();// take a snapshotif (snapInProcess != null && snapInProcess.isAlive()) { LOG.warn("Too busy to snap, skipping");} else { snapInProcess = new ZooKeeperThread("Snapshot Thread") { public void run() { try { zks.takeSnapshot(); } catch(Exception e) { LOG.warn("Unexpected exception", e); } } }; snapInProcess.start();}logCount = 0; } } else if (toFlush.isEmpty()) { // optimization for read heavy workloads // iff this is a read, and there are no pending // flushes (writes), then just pass this to the next // processor if (nextProcessor != null) {nextProcessor.processRequest(si);if (nextProcessor instanceof Flushable) { ((Flushable)nextProcessor).flush();} } continue; } toFlush.add(si); if (toFlush.size() > 1000) { flush(toFlush); } } } }}我们看到,在run方法的第一步,定义了一个变量
int logCount = 0;从名称可以看出这是记录事务日志条数的.
然后,run方法有两个地方调用了flush方法:
Request si = null;if (toFlush.isEmpty()) {si = queuedRequests.take();} else {si = queuedRequests.poll(); if (si == null) { flush(toFlush); continue; }} ... toFlush.add(si);if (toFlush.size() > 1000) { flush(toFlush);} 先看第一处:
调用flush的前提是:toFlush不为空并且当前queuedRequests请求队列没有请求.
private final LinkedList toFlush = new LinkedList();从toFlush的定义来看,它是一组请求,并且是被flush函数调用的,可想而之,它是一组待flush到磁盘的请求,即待flush到磁盘的事务日志.
从此我们得到一个答案:
zookeeper的事务日志是按组flush到磁盘的.flush的时机时:
- 当前无请求处理,并且有需要flush到磁盘的事务日志,则触发flush操作
- 如果当前写请求很多,需要flush到磁盘的事务日志,累计到了大于1000个时,也会触发flush操作
接下来我们看下这段代码:
if (zks.getZKDatabase().append(si)) { logCount++; if (logCount > (snapCount / 2 + randRoll)) { randRoll = r.nextInt(snapCount/2); // roll the log zks.getZKDatabase().rollLog(); // take a snapshot if (snapInProcess != null && snapInProcess.isAlive()) { LOG.warn("Too busy to snap, skipping"); } else { snapInProcess = new ZooKeeperThread("Snapshot Thread") { public void run() { try { zks.takeSnapshot(); } catch(Exception e) { LOG.warn("Unexpected exception", e); } } }; snapInProcess.start(); } logCount = 0; }}首先:
zks.getZKDatabase().append(si) /**ZKDatabase * append to the underlying transaction log * @param si the request to append * @return true if the append was succesfull and false if not */ public boolean append(Request si) throws IOException { return this.snapLog.append(si); }这里的snapLog是指:FileTxnSnapLog,该类是zookeeper的事务日志txnLog和快照snapLog的一个工具类.
public class FileTxnSnapLog { //the direcotry containing the //the transaction logs private final File dataDir; //the directory containing the //the snapshot directory private final File snapDir; private TxnLog txnLog; private SnapShot snapLog; public boolean append(Request si) throws IOException { return txnLog.append(si.getHdr(), si.getTxn()); } }其中txnLog代表了事务日志.
我们看下在添加完事务日志成功后,又做了什么?
logCount++; if (logCount > (snapCount / 2 + randRoll)) { randRoll = r.nextInt(snapCount/2); // roll the log zks.getZKDatabase().rollLog(); // take a snapshot if (snapInProcess != null && snapInProcess.isAlive()) { LOG.warn("Too busy to snap, skipping"); } else { snapInProcess = new ZooKeeperThread("Snapshot Thread") { public void run() { try { zks.takeSnapshot(); } catch(Exception e) { LOG.warn("Unexpected exception", e); } } }; snapInProcess.start(); } logCount = 0; }- 首先: logCount计数加一
- 判断当前logCount是否大于snapCount/2+randRoll
- snapCount:我们从上面定义看出该变量是代表了经过几次事务日志后,会进行生成快照操作
- randRoll:一个随机数,范围[0,snapCount/2]
- 如果上面判断为true,
- 执行zks.getZKDatabase().rollLog();这就是事务日志的切分
- 判断是否要进行快照生成
- 如果生成快照的线程已经存在,并且alive,说明当前上次的生成快照流程还未结束,直接跳过
- 如果生成快照的线程不存在,则创建一个线程生成快照
- logCount计数重置
通过这段代码的梳理我们得到以下结论:
- 事务日志是存到不同的事务文件的,按照一定的规则进行roll生成
- 事务日志roll和快照生成时机有snapCount来控制,默认是10000
接下来我们深入看下以下几个地方
- 事务日志的切分
- 事务日志的格式
- 按组flush事务日志,是如果保证全部成功的.
在回答这三个问题之前,先看下下面几个存储知识.
2.3.2.存储知识背景
2.3.1.1.WAL-Wirte Ahead Log
什么是WAL?
WAL是广泛使用的保证多Block数据写入原子性的技术.WAL就是在对block进行写入之前,先把新的数据写到一个日志,只有在写入END日志并调用sync API,才对block进行写入.如果在对block进行写入的任何时候发生crash,都可以在重启的的时候使用WAL里面的数据完成block的写入.
原理图如下:
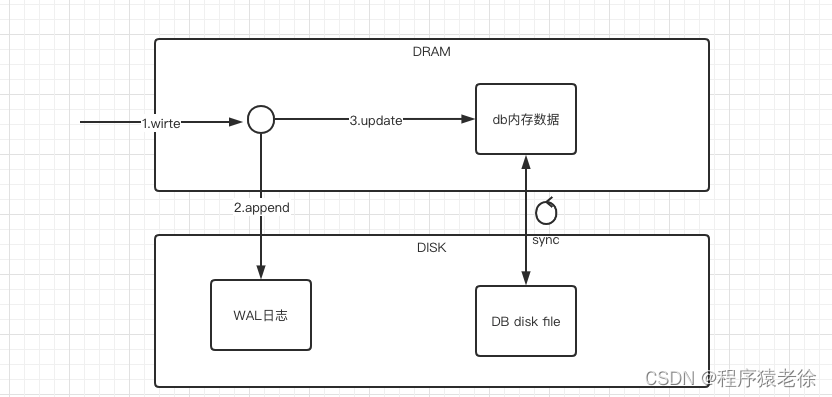
WAL是保证数据完整性的一种标准方法.简单来说,WAL的中心概念是数据文件的修改必须在这些动作被日志记录之后才能被写入,即在描述这些改变的日志记录被刷到持久存储以后. 如果我们遵守这种过程,我们不需要在每个事务提交时刷写数据页面到磁盘,因为我们知道在发生崩溃时可以使用日志来恢复数据库:
任何还没有被应用到数据页的改变可以根据其日志重做.
WAL日志一般会和快照文件一起工作,快照文件保存了全量数据在某一个时刻的一种状态,在恢复数据时,先通过快照文件恢复某一时刻的全量数据,然后根据事务日志将那一时刻之后的数据进行恢复.
所以WAL一般有以下特点:
- WAL文件一般有多个,并且是有序的
- WAL文件内的每一条记录,存在一个递增事务id,在恢复时,可以根据该id与快照文件中最后一个事务id做比较,如果大于快照文件中的事务id,则说明该事务(数据变更)是在快照文件生成后发生的,需要恢复
- WAL文件一般是顺序写的,相比于数据文件的写入(非顺序写)效率要高
2.3.1.2.WAL的优化
2.3.1.2.1.Group Commit
在写入WAL日志时,如果每增加一次记录变更写入,就调用fsync,将日志数据刷新到磁盘,会影响系统的性能.
为了解决这个问题,提出了Group Commit概念,即一次提交多个数据,调用一次fsync,将这几次变更一次刷到磁盘.
但是这样就会出现一致性问题,即这一组待刷新的变更,不能保证都刷新成功.
2.3.1.2.2.File Padding
在往WAL日志里面append内容时,如果剩余的空间不能保证保存新的日志,就需要为WAL文件分配新的空间,而分配新的空间是比较耗时的,所以可以事先为WAL分配存储空间.
2.3.1.2.3.Snapshot
如果我们使用一个内存结构+WAL日志的存储方案来做存储,WAL日志会变的非常大,进而导致恢复时耗时很长.
所以我们一般会生成一个快照snapshot文件,一个快照文件保存了某一个时刻时全量数据的最新状态.
2.3.3.ZooKeeper对WAL的实践
2.3.3.1.事务日志
在ZooKeeper中FileTxnLog是对事务日志TxnLog接口的一个实现,我们看下事务日志接口TxnLog定了哪些内容:
public interface TxnLog { //状态监控类 void setServerStats(ServerStats serverStats); // 生成新的文件 void rollLog() throws IOException; //向事务日志追加记录 boolean append(TxnHeader hdr, Record r) throws IOException; //根据某一个zxid,来读取事务日志,返回一个迭代器 TxnIterator read(long zxid) throws IOException; //返回事务日志的最后一个zxid long getLastLoggedZxid() throws IOException; //根据zxid截断事务日志 boolean truncate(long zxid) throws IOException; //返回事务日志所属的dbid long getDbId() throws IOException; //提交事务日志,确保事务日志刷到磁盘 void commit() throws IOException; //事务日志刷到磁盘所用耗时 long getTxnLogSyncElapsedTime(); //关闭事务日志 void close() throws IOException; /** * 事务日志迭代器 */ public interface TxnIterator { TxnHeader getHeader(); Record getTxn(); boolean next() throws IOException; void close() throws IOException; long getStorageSize() throws IOException; }}我们先来看下append操作
/** * append an entry to the transaction log * @param hdr the header of the transaction * @param txn the transaction part of the entry * returns true iff something appended, otw false */ public synchronized boolean append(TxnHeader hdr, Record txn) throws IOException { if (hdr == null) { return false; } if (hdr.getZxid() <= lastZxidSeen) { LOG.warn("Current zxid " + hdr.getZxid() + " is <= " + lastZxidSeen + " for " + hdr.getType()); } else { lastZxidSeen = hdr.getZxid(); } if (logStream==null) { if(LOG.isInfoEnabled()){ LOG.info("Creating new log file: " + Util.makeLogName(hdr.getZxid())); } logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid())); fos = new FileOutputStream(logFileWrite); logStream=new BufferedOutputStream(fos); oa = BinaryOutputArchive.getArchive(logStream); FileHeader fhdr = new FileHeader(TXNLOG_MAGIC,VERSION, dbId); fhdr.serialize(oa, "fileheader"); // Make sure that the magic number is written before padding. logStream.flush(); filePadding.setCurrentSize(fos.getChannel().position()); streamsToFlush.add(fos); } filePadding.padFile(fos.getChannel()); byte[] buf = Util.marshallTxnEntry(hdr, txn); if (buf == null || buf.length == 0) { throw new IOException("Faulty serialization for header " + "and txn"); } Checksum crc = makeChecksumAlgorithm(); crc.update(buf, 0, buf.length); oa.writeLong(crc.getValue(), "txnEntryCRC"); Util.writeTxnBytes(oa, buf); return true; }事务日志文件名称:
if (logStream==null) { logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));}public static final String LOG_FILE_PREFIX = "log";public static String makeLogName(long zxid) { return FileTxnLog.LOG_FILE_PREFIX + "." + Long.toHexString(zxid);}如果当前没有在使用的事务日志,则根据当前请求的zxid,创建事务日志文件,所以事务日志文件名称格式为: log.{zixd}
确保了事务日志文件名称是递增的.
2.3.3.1.1.File Padding
我们在来看下zookeeper是如何做padding的?
filePadding.padFile(fos.getChannel()); long padFile(FileChannel fileChannel) throws IOException { long newFileSize = calculateFileSizeWithPadding(fileChannel.position(), currentSize, preAllocSize); if (currentSize != newFileSize) { fileChannel.write((ByteBuffer) fill.position(0), newFileSize - fill.remaining()); currentSize = newFileSize; } return currentSize; } public static long calculateFileSizeWithPadding(long position, long fileSize, long preAllocSize) { // If preAllocSize is positive and we are within 4KB of the known end of the file calculate a new file size if (preAllocSize > 0 && position + 4096 >= fileSize) { // If we have written more than we have previously preallocated we need to make sure the new // file size is larger than what we already have if (position > fileSize) { fileSize = position + preAllocSize; fileSize -= fileSize % preAllocSize; } else { fileSize += preAllocSize; } } return fileSize; }如果当前的写入位置position + 4096(4k) 大于当前的文件大小,默认扩展大小为64M.
2.3.3.1.2.Group Commit
我们前面在SyncRequestProcessor中提到过,flush的两个时机:
//1.时机1Request si = null;if (toFlush.isEmpty()) { si = queuedRequests.take();} else { si = queuedRequests.poll(); if (si == null) { flush(toFlush); continue; }}//时机二toFlush.add(si);if (toFlush.size() > 1000) {flush(toFlush);}这里flush操作,就是提交一组事务日志,flush函数如下:
private void flush(LinkedList<Request> toFlush) throws IOException, RequestProcessorException { if (toFlush.isEmpty()) return; zks.getZKDatabase().commit(); while (!toFlush.isEmpty()) { Request i = toFlush.remove(); if (nextProcessor != null) { nextProcessor.processRequest(i); } } if (nextProcessor != null && nextProcessor instanceof Flushable) { ((Flushable)nextProcessor).flush(); } } //ZKDatabase /** * commit to the underlying transaction log * @throws IOException */ public void commit() throws IOException { this.snapLog.commit(); } //FileTxnSnapLog /** * commit the transaction of logs * @throws IOException */ public void commit() throws IOException { txnLog.commit(); } /** * commit the logs. make sure that everything hits the * disk */ public synchronized void commit() throws IOException { if (logStream != null) { logStream.flush(); } for (FileOutputStream log : streamsToFlush) { log.flush(); if (forceSync) { long startSyncNS = System.nanoTime(); FileChannel channel = log.getChannel(); channel.force(false); syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS); if (syncElapsedMS > fsyncWarningThresholdMS) { if(serverStats != null) { serverStats.incrementFsyncThresholdExceedCount(); } LOG.warn("fsync-ing the write ahead log in "+ Thread.currentThread().getName()+ " took " + syncElapsedMS+ "ms which will adversely effect operation latency. "+ "File size is " + channel.size() + " bytes. "+ "See the ZooKeeper troubleshooting guide"); } } } while (streamsToFlush.size() > 1) { streamsToFlush.removeFirst().close(); } }commit操作就是对当前还未刷到磁盘的事务日志进行强制调用fsync操作,
channel.force(false);并将除了最后一个事务日志之前的事务日志数据流进行关闭.
2.3.3.1.3.Snapshot快照文件
zookeeper中触发快照文件生成的操作也是在SyncRequestProcessor中,
snapInProcess = new ZooKeeperThread("Snapshot Thread") { public void run() {try { zks.takeSnapshot();} catch(Exception e) { LOG.warn("Unexpected exception", e);} } }; snapInProcess.start();快照的生成,是对内存中DataTree的序列化操作:
public synchronized void serialize(DataTree dt, Map<Long, Integer> sessions, File snapShot) throws IOException { if (!close) { try (OutputStream sessOS = new BufferedOutputStream(new FileOutputStream(snapShot)); CheckedOutputStream crcOut = new CheckedOutputStream(sessOS, new Adler32())) { //CheckedOutputStream cout = new CheckedOutputStream() OutputArchive oa = BinaryOutputArchive.getArchive(crcOut); FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId); serialize(dt, sessions, oa, header); long val = crcOut.getChecksum().getValue(); oa.writeLong(val, "val"); oa.writeString("/", "path"); sessOS.flush(); } } }序列化工具是apache的jute,有兴趣的可以看下,序列化方式,就是对DataTree进行前序遍历.
这里不过多介绍了.
2.3.3.2.数据恢复
当zookeeper服务重启时,需要从snapshot文件和事务文件中恢复数据,我们看下时如何操作的?
FileTxnSnapLog
public long restore(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException { long deserializeResult = snapLog.deserialize(dt, sessions); FileTxnLog txnLog = new FileTxnLog(dataDir); if (-1L == deserializeResult) { /* this means that we couldn't find any snapshot, so we need to * initialize an empty database (reported in ZOOKEEPER-2325) */ if (txnLog.getLastLoggedZxid() != -1) { throw new IOException( "No snapshot found, but there are log entries. " + "Something is broken!"); } /* TODO: (br33d) we should either put a ConcurrentHashMap on restore() *or use Map on save() */ save(dt, (ConcurrentHashMap<Long, Integer>)sessions); /* return a zxid of zero, since we the database is empty */ return 0; } return fastForwardFromEdits(dt, sessions, listener); }//从事务日志里面恢复数据 public long fastForwardFromEdits(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException { TxnIterator itr = txnLog.read(dt.lastProcessedZxid+1); long highestZxid = dt.lastProcessedZxid; TxnHeader hdr; try { while (true) { // iterator points to // the first valid txn when initialized hdr = itr.getHeader(); if (hdr == null) { //empty logs return dt.lastProcessedZxid; } if (hdr.getZxid() < highestZxid && highestZxid != 0) { LOG.error("{}(highestZxid) > {}(next log) for type {}",highestZxid, hdr.getZxid(), hdr.getType()); } else { highestZxid = hdr.getZxid(); } try { processTransaction(hdr,dt,sessions, itr.getTxn()); } catch(KeeperException.NoNodeException e) { throw new IOException("Failed to process transaction type: " + hdr.getType() + " error: " + e.getMessage(), e); } listener.onTxnLoaded(hdr, itr.getTxn()); if (!itr.next()) break; } } finally { if (itr != null) { itr.close(); } } return highestZxid; }该函数主要有以下操作:
- 反序列化snapLog,返回snapLog中最大的zxid
- 如果返回结果为-1,说明当前没有生成snapLog,
- 如果当前的txnLog事务日志的最后的zxid事务id不为-1,说明当前有事务日志,抛出异常
- 生成一个空的DataTree,并返回最大事务id为0
- 从snapLog返回的zxid开始查找txnLog中的事务记录,并加载到DataTree中
- 如果返回结果为-1,说明当前没有生成snapLog,
到此,对zookeeper存储原理的梳理基本完成,有些细节和集群方式下的数据请求处理、存储恢复后面再出文章详细介绍.
 开发者涨薪指南
开发者涨薪指南  48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系

