linux内核源码分析之物理内存组织结构
目录
体系结构
内存模型
三级结构
1、内存节点(pglist_data)
2、内存区域(zone)
3、物理页(page)
页表
体系结构
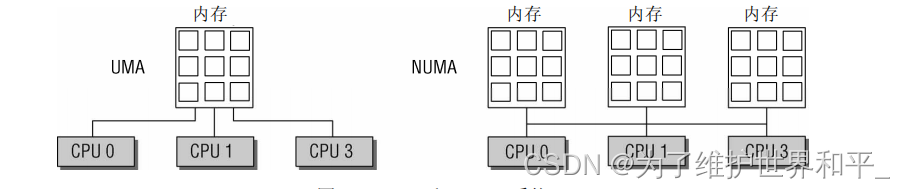
目前多处理器系统有两种体系结构:
- 非一致内存访问(Non-Unit Memory Access,NUMA):指内存被划分成多个 内存节点的多处理器系统。访问一个内存节点花费的时间取决于处理器和内存节点的距离。
- 对称多处理器(Symmetric Multi-Processor,SMP):即一致内存访问 (Uniform Memory Access,UMA),所有处理器访问内存花费的时间是相同。
内存模型
内存模型是从处理器角度看到的物理内存分布,内核管理不同内存模型的方式存差异。
内存管理子系统支持3种内存模型:
- 平坦内存(Flat Memory):内存的物理地址空间是连续的,没有空洞。
- 不连续内存(Discontiguous Memory):内存的物理地址空间存在空洞,这种模型可以高效地处理空洞。
- 稀疏内存(Space Memory):内存的物理地址空间存在空洞,如果要支持内存热 插拔,只能选择稀疏内存模型。
三级结构
内存管理子系统使用节点(node),区域(zone)、页(page)三级结构描述物理内存
1、内存节点(pglist_data)
分为两种情况:
a,NUMA体系的内存节点,根据处理器和内存的距离划分;
b,在具有不连续内存的NUMA系统中,表示比区域的级别更高的内存区域,根据物 理地址是否连续划分,每块物理地址连续的内存是一个内存节点。
typedef struct pglist_data {struct zone node_zones[MAX_NR_ZONES];//内存区域数组struct zonelist node_zonelists[MAX_ZONELISTS];//备用区域列表int nr_zones;//该节点包含的内存区域数量#ifdef CONFIG_FLAT_NODE_MEM_MAP/* means !SPARSEMEM */struct page *node_mem_map;#ifdef CONFIG_PAGE_EXTENSIONstruct page_ext *node_page_ext;//页的扩展属性#endif#endifunsigned long node_start_pfn;//该节点的起始物理页号unsigned long node_present_pages; /* 物理页总数total number of physical pages */unsigned long node_spanned_pages; /* 物理页范围的总长度,包括空洞total size of physical page range, including holes */int node_id;//节点标识符 ...}2、内存区域(zone)
类型 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM,ZONE_MOVABLE等
- ZONE_DMA标记适合DMA的内存域。该区域的长度依赖于处理器类型。在IA-32计算机上,一般的限制是16 MiB
- ZONE_DMA32标记了使用32位地址字可寻址、适合DMA的内存域。显然,只有在64位系统上, 两种DMA内存域才有差别。在32位计算机上,本内存域是空的,即长度为0 MiB。在Alpha和 AMD64系统上,该内存域的长度可能从0到4 GiB。
- ZONE_NORMAL标记了可直接映射到内核段的普通内存域。这是在所有体系结构上保证都会存在的唯一内存域,但无法保证该地址范围对应了实际的物理内存。例如,如果AMD64系统有2 GiB 内存,那么所有内存都属于ZONE_DMA32范围,而ZONE_NORMAL则为空。
- ZONE_HIGHMEM标记了超出内核段的物理内存。
内存节点被划分为内存区域。Linux内核源码分析:include/linux/mmzone.h
enum zone_type {//DMA区域,直接内存访问。如果有些设备不能直接访问所有内存,需要使用DMA区域#ifdef CONFIG_ZONE_DMAZONE_DMA,#endif//DMA32区域64位系统,如果既要支持只能直接访问16MB以下的内存设备,又要支持只能直接访问4GB以下//内存的32设备,必须使用此DMA32区域#ifdef CONFIG_ZONE_DMA32ZONE_DMA32,#endif/* * Normal addressable memory is in ZONE_NORMAL. DMA operations can be * performed on pages in ZONE_NORMAL if the DMA devices support * transfers to all addressable memory. *///普通区域:直接映射到内核虚拟地址空间的内存区域,又称为普通区域ZONE_NORMAL,#ifdef CONFIG_HIGHMEM/* * A memory area that is only addressable by the kernel through * mapping portions into its own address space. This is for example * used by i386 to allow the kernel to address the memory beyond * 900MB. The kernel will set up special mappings (page * table entries on i386) for each page that the kernel needs to * access. *///高端内存区域:内核和用户地址空间按1:3划分,内核地址空间只有1GB,不能把1GB以上的//内存直接映射到内核地址ZONE_HIGHMEM,#endif//可移动区域:它是一个伪内存区域,用来放在内存碎片ZONE_MOVABLE,#ifdef CONFIG_ZONE_DEVICE//设备区域:支持持久内存热插拔增加的内存区域,每个内存区域有一个zone结构体来描述ZONE_DEVICE,#endif__MAX_NR_ZONES};每个内存区域使用一个zone结构体描述
struct zone {/* zone watermarks, access with *_wmark_pages(zone) macros */unsigned long _watermark[NR_WMARK];//页分配器使用的水线unsigned long watermark_boost;unsigned long nr_reserved_highatomic;long lowmem_reserve[MAX_NR_ZONES];//当前区域预留多少页不能给高位的区域类型#ifdef CONFIG_NUMAint node;#endifstruct pglist_data*zone_pgdat;struct per_cpu_pageset __percpu *pageset; .../* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */unsigned longzone_start_pfn;//当前区域的起始 /* 伙伴分配器管理的物理页数量 * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): *managed_pages = present_pages - reserved_pages; */ atomic_long_tmanaged_pages;/* * 当前区域跨越的总页数,包括空洞 * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; */unsigned longspanned_pages; /* 当前区域存在的物理页的数量,不包括空洞 * present_pages is physical pages existing within the zone, which * is calculated as: *present_pages = spanned_pages - absent_pages(pages in holes); */unsigned longpresent_pages;const char*name;int initialized;/* Write-intensive fields used from the page allocator */ZONE_PADDING(_pad1_)/* free areas of different sizes */struct free_areafree_area[MAX_ORDER];//不同长度的空间区域/* zone flags, see below */unsigned longflags;/* Primarily protects free_area */spinlock_tlock;/* Write-intensive fields used by compaction and vmstats. */ZONE_PADDING(_pad2_) ...}冷热页
struct zone的pageset成员用于实现冷热分配器。
热页:意味着已经加载到cpu高度缓存,与内存中的页相比,其数据结构能够快速访问。
冷页:不在高速缓存中。
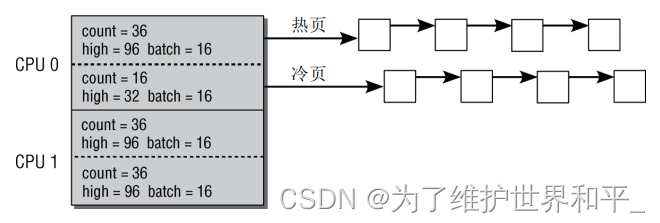
在多处理器系统上每个CPU都有一个或者多个高速缓存,各CPU的管理必须是独立的。
struct per_cpu_pageset __percpu *pageset;
struct per_cpu_pages {int count;/* number of pages in the list */int high;/* high watermark, emptying needed */int batch;/* chunk size for buddy add/remove *//* Lists of pages, one per migrate type stored on the pcp-lists */struct list_head lists[MIGRATE_PCPTYPES];};count记录了与该列表相关的页的数目,high是一个水印。如果count的值超出了high,则表明
列表中的页太多了。对容量过低的状态没有显式使用水印:如果列表中没有成员,则重新填充。
如有可能,CPU的高速缓存不是用单个页来填充的,而是用多个页组成的块。batch是每次添加页数的一个参考值。
下图说明了在双处理器系统上per-CPU缓存的数据结构式如何填充的。
3、物理页(page)
页是内存管理当中最小单位,页面中的内存其物理地址是连续的。
页,在内核中,内存管理单元MMU把物理页page作为内存管理的基本单位,
不同体系结构,支持的页大小页也不同
32位体系结构支持4kb的页
64位体系结构支持8kb的页
MIPS64架构体系支持16kb的页
每个物理页对应一个page结构体,称为页描述符,内存节点的pglist_data实例的成员node_mem_map指向该内存节点包含的所有物理页的页描述符组成的数组。Linux内核源码分
析:include/linux/mm_types.h
struct page {unsigned long flags;//原子标志,有些情况下会异步更新union {struct {/* Page cache and anonymous pages */struct list_head lru;//如果最低位位0,则指向inode address_space 或为NULL//如果页映射为匿名地址,最低位置位,而且指针指向anon_vma对象struct address_space *mapping;pgoff_t index;/* Our offset within mapping. *///由映射私有,不透明数据;//如果设置了PagePrivate,通常用于buffer_heads,//如果设置了PageSwapCache,则用于swp_entry_t//如果设置了PageBuddy 则用于伙伴系统中的阶unsigned long private;};struct {/* slab, slob and slub */union {struct list_head slab_list;struct {/* Partial pages */struct page *next;#ifdef CONFIG_64BITint pages;/* Nr of pages left */int pobjects;/* Approximate count */#elseshort int pages;short int pobjects;#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist;/* first free object */union {void *s_mem;/* slab: first object */unsigned long counters;/* SLUB */struct {/* SLUB */unsigned inuse:16;unsigned objects:15;unsigned frozen:1;};};};...}页表
层次化的页表用于支持对大地址空间的快速、高效的管理。
1. 内存地址的分解
根据四级页表结构的需要,虚拟内存地址分为5部分(4个表项用于选择页,1个索引表示页内位置)。分解虚拟内存地址如下
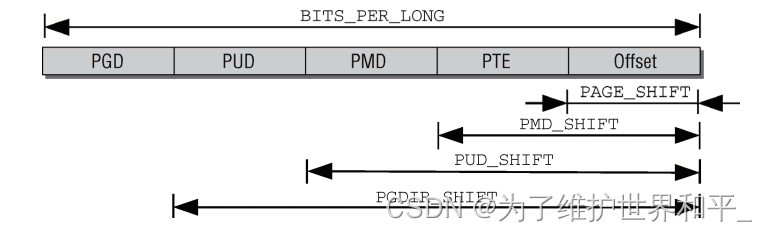
- 每个指针末端的几个比特位,用于指定所选页帧内部的位置。比特位的具体数目由PAGE_SHIFT 指定。
- PMD_SHIFT指定了页内偏移量和最后一级页表项所需比特位的总数。该值减去PAGE_SHIFT,可得 最后一级页表项索引所需比特位的数目。
-
PUD_SHIFT由 PMD_SHIFT加上中间层页表索引所需的比特位长度,而 PGDIR_SHIFT则 由
PUD_SHIFT加上上层页表索引所需的比特位长度。对全局页目录中的一项所能寻址的部分地址空间长度计算以2为底的对数,即为PGDIR_SHIFT。
2. 页表的格式
上述定义已经确立了页表项的数目,但没有定义其结构,内核提供了4个数据结构(定义在page.h中)来表示页表项的结构。
- pgd_t用于全局页目录项
- pud_t用于上层页目录项
- pmd_t用于中间页目录项
- pte_t用于直接页表项
3. 特定于PTE的信息
最后一级页表中的项不仅包含了指向页的内存位置的指针,还在上述的多余比特位包含了与页有 关的附加信息。
每种体系结构都必须提供两个东西,使得内存管理子系统能够修改pte_t项中额外的比特位,即保存额外的比特位的__pgprot数据类型,以及修改这些比特位的pte_modify函数。
内核还定义了各种函数,用于查询和设置内存页与体系结构相关的状态。
| 函数 | 描述 |
|
pte_present |
页在内存中吗 |
|
pte_read |
可以写入到该页吗 |
|
pte_write |
可以写入到该页吗 |
|
pte_exec |
该页中的数据可以作为二进制代码执行吗 |
|
pte_dirty |
页是脏的吗?其内容是否修改过 |
|
pte_file |
该页表项属于非线性映射吗 |
|
pte_young |
访问位(通常是_PAGE_ACCESS)设置了吗 |
|
pte_rdprotect |
清除该页的读权限 |
|
pte_wrprotect |
清除该页的写权限 |
|
pte_exprotect |
清除执行该页中二进制数据的权限 |
|
pte_mkread |
设置读权限 |
|
pte_mkwrite |
设置写权限 |
|
pte_mkexec |
允许执行页的内容 |
页表项的创建和操作
|
函 数 |
描 述 |
|
mk_pte |
创建一个页表项。必须将page实例和所需的页访问权限作为参数传递 |
|
pte_page |
获得页表项描述的页对应的page实例地址 |
|
pgd_alloc |
分配并初始化可容纳一个完整页表的内存 |
|
pgd_free |
释放页表占据的内存 |
|
set_pgd |
设置页表中某项的值 |
所有体系结构都必须实现表中的函数,以便内存管理代码创建和销毁页表。
参考
《深入linux内核架构》
剖析Linux内核物理内存管理-大学生教程-腾讯课堂
 创作打卡挑战赛
创作打卡挑战赛  赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖

